# 一、Numba 简介
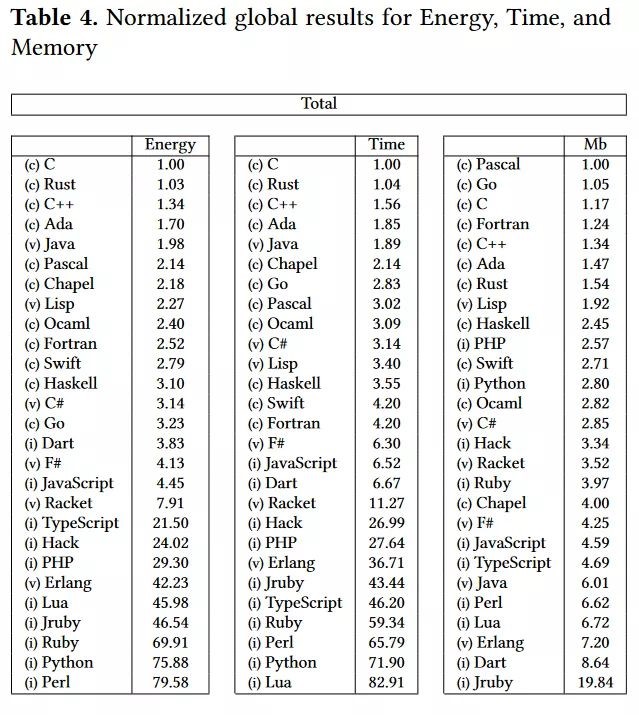
计算机只能执行二进制的机器码, C 、 C++ 等编译型语言依靠编译器将源代码转化为可执行文件后才能运行, Python 、 Java 等解释型语言使用解释器将源代码翻译后在虚拟机上执行。对于 Python ,由于解释器的存在,其执行效率比 C 语言慢几倍甚至几十倍。通过下图对各种编程语言比较情况可见 python 在消耗电量、速度以及内存使用情况上与 C 、 C++ 的差距。
Numba 是一个针对 Python 的开源 JIT 编译器,由 Anaconda 公司主导开发,可以对原生代码进行 CPU 和 GPU 加速。在使用 Python 进行高性能计算时, Numba 提供的加速效果可以比肩原生的 C/C++ 程序。
# 二、numba 的使用方式
通常,在对 Python 函数应用函数装饰器后,便可启用 Numba 编译器。装饰器即为函数修改器,使用十分简单的语法来转换所装饰的 Python 函数。
# 2.1 @jit
我们只需要在原来的代码上添加一行 @jit ,即可将一个函数编译成机器码,其他地方都不需要更改。 @ 符号装饰了原来的代码,所以称类似写法为装饰器。
from numba import jit | |
import numpy as np | |
a = np.arange(10) | |
b = np.arange(1,11) | |
@jit | |
def test(): | |
return a+b | |
test() |
# 2.2 @njit
@jit 装饰器有一个参数 nopython , 用于区分 numba 的运行模式, numba 有两种运行模式:一个是 nopython 模式,另一个就是 object 模式。只有在 nopython 模式下,才会获得最好的加速效果,如果 numba 发现代码有不能理解的东西,就会自动进入 object 模式,确保程序能够运行的。将装饰器改为 @jit(nopython=True) 或者 @njit , numba 会强制使用加速的方式,不进入 object 模式,如编译不成功,则直接抛出异常。
from numba import jit | |
import numpy as np | |
a = np.arange(10) | |
b = np.arange(1,11) | |
@njit # 相当于 @jit (nonpyhon=True) | |
def test(): | |
return a+b | |
test() |
# 2.3 @vectorize
通过使用 @vectorize 装饰器,你可以对仅能对标量操作的函数进行转换,例如,如果你使用的是仅适用于标量的 python 的 math 库,则转换后就可以用于数组。这提供了类似于 numpy 数组运算。
from numba import jit, int32 | |
@vectorize | |
def func(a, b): | |
# Some operation on scalars | |
return result |
# 三、使用注意事项
(1) Numba 简单到只需要在函数上加一个装饰就能加速程序,但也有缺点。目前 Numba 只支持了 Python 原生函数和部分 NumPy 函数,其他一些场景可能不适用。
比如类似 pandas 这样的库是更高层次的封装, Numba 其实不能理解它里面做了什么,所以无法对其加速。一些大家经常用的机器学习框架,如 scikit-learn , tensorflow , pytorch 等,已经做了大量的优化,不适合再使用 Numba 做加速。
(2)原生 Python 速度慢的另一个重要原因是变量类型不确定。声明一个变量的语法很简单,如 a = 1 ,但没有指定 a 到底是一个整数和一个浮点小数。 Python 解释器要进行大量的类型推断,会非常耗时。 引入 Numba 后, Numba 也要推断输入输出的类型,才能转化为机器码。针对这个问题, Numba 给出了名为 Eager Compilation 的优化方式。
from numba import jit, int32 | |
@jit("int32(int32, int32)", nopython=True) | |
def f2(x, y): | |
return x + y |
@jit(int32(int32, int32)) 告知 Numba 你的函数在使用什么样的输入和输出,括号内是输入,括号左侧是输出。这样不会加快执行速度,但是会加快编译速度,可以更快将函数编译到机器码上。
# 四、成功使用案例
# 功能:根据输入参数获得 z(货架 i 为订单 o 提供的商品 c 的数量) | |
# 输入参数:各参数同 parameter.py | |
# 输出参数:z | |
@nb.njit( | |
nb.types.Array(nb.int32, 3, "C")(nb.types.Array(nb.int32, 2, "C"), nb.types.Array(nb.int32, 1, "C"), nb.types.Array(nb.int32, 2, "C"), | |
nb.types.Array(nb.int32, 2, "C"))) | |
def get_z(y, selected_pods, A, B): | |
z = np.zeros((y.shape[0], B.shape[0], B.shape[1]), dtype=nb.int32) | |
transform_y = [] | |
for i in range(selected_pods.shape[0]): | |
for j in range(y.shape[0]): | |
if y[j, i] == 1: | |
transform_y.append(j) | |
break | |
remaining_orders = np.copy(B) # 所有订单剩余量(n_order*n_commodity_type) | |
for i in range(selected_pods.shape[0]): # 第 i 个货架 | |
remaining_A = np.copy(A[transform_y[i]]) # 当前货架的剩余量(1*n_commodity_type) | |
for j in range(B.shape[0]): # 第 j 个订单 | |
for k in range(B.shape[1]): # 第 k 种商品 | |
if remaining_A[k] > 0 and remaining_orders[j, k] > 0: | |
if remaining_A[k] >= remaining_orders[j, k]: # 货架 i 足够为订单 k 提供 z 种商品 | |
z[transform_y[i], j, k] = remaining_orders[j, k] | |
remaining_A[k] = remaining_A[k] - remaining_orders[j, k] | |
remaining_orders[j, k] = 0 | |
else: # 货架 i 不足够为订单 k 提供 z 种商品 | |
# z[transform_y[i]][j][k] = remaining_A[k] | |
z[transform_y[i], j, k] = remaining_A[k] | |
remaining_orders[j, k] = remaining_orders[j, k] - remaining_A[k] | |
remaining_A[k] = 0 | |
return z |