参考链接:https://waylandzhang.github.io/en/transformer-architecture.html#4-7-calculate-v-attention、https://space.bilibili.com/3546611527453161?spm_id_from=333.788.0.0、https://nlp.seas.harvard.edu/2018/04/03/attention.html
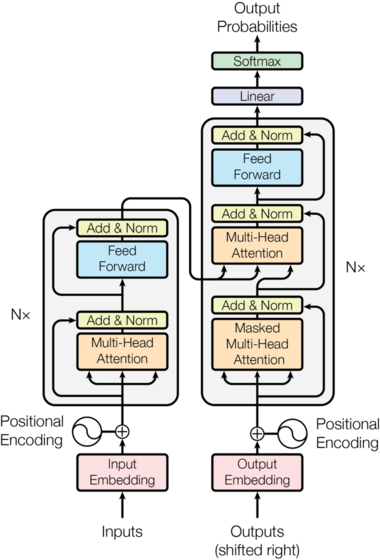
Transformer 模型由两部分组成:编码器和解码器。一般来说,仅编码器的架构精通于从文本中提取信息,用于分类和回归等任务,而仅解码器的模型专门用于生成文本。例如,专注于文本生成的 GPT 属于仅解码器模型的类别。
Transformer 的大致过程如下:
- 首先,我们需要一系列输入字符作为训练数据。这些输入被转换成矢量嵌入格式。
- 接下来,我们将位置编码添加到矢量嵌入中,以捕获序列中每个字符的位置。
- 随后,该模型通过一系列计算操作处理这些输入嵌入,最终为给定的输入文本生成可能的下一个字符的概率分布。
- 该模型根据训练数据集中的实际后续特征来评估预测结果,并相应地调整概率或 “权重”。
- 最后,该模型迭代地细化这个过程,不断更新其参数,以提高未来预测的精度。
# 一、Tokenizer
Tokenizer 分词算法是 NLP 大模型最基础的组件,基于 Tokenizer 可以将文本转换成独立的 token 列表,进而转换成输入的向量成为计算机可以理解的输入形式。
tiktoken 是一种快速 BPE 标记器,可与 OpenAI 模型一起使用。
tiktoken 使用方法为:
import tiktoken | |
# Using TikToken (Same as GPT3) to tokenize the source text | |
encoding = tiktoken.get_encoding("cl100k_base") | |
# text 保存了 str 变量类型的文本内容 --> 输出为以单词为单位的 int 列表 | |
tokenized_text = encoding.encode(text) | |
# 将 tokenized_text 转换为 Tensor.int64 类型的张量 | |
tokenized_text = torch.tensor(tokenized_text, dtype=torch.long, device=device) |
上述的代码提供了 encoding 的编码过程,同时还可以根据 tokenized 的编码结果进行解码,只需要通过 decode 函数输入 int 类型的列表集合返回原始的 str 类型文本
# 输出单个编码对应的 str 文本 | |
print(encoding.decode([int(tokenized_text[0])])) | |
# 输出多个编码对应的 str 文本 | |
print(encoding.decode(tokenized_text.tolist())) |
# 二、Embedding
Tokenize 完的下一步就是将 token 的 one-hot 编码转换成更 dense 的 embedding 编码。
Embedding 矩阵的本质就是一个查找表。由于输入向量是 one-hot 的, embedding 矩阵中有且仅有一行被激活。行间互不干扰。如下图所示,假设词汇表一共有 6 个词,则 one-hot 表示的长度为 6 。现在我们有三个单词组成一个句子,则输入矩阵的形状为 (3,6) 。然后我们学出来一个 embedding 矩阵,根据上面的推导,如果我们的 embedding size (编码向量的长度)为 4 ,则 embedding 矩阵的形状应该为 (6,4) 。这样乘出来的输出矩阵的形状应为 (3,4) 。
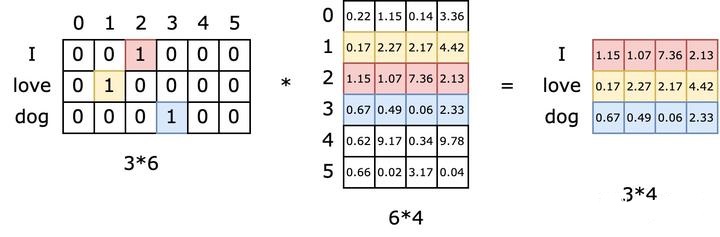
对于第一个单词 I ,假设其 one-hot 编码为 [0,0,1,0,0,0] ,将其与 embedding 矩阵相乘,相当于取出 embedding 矩阵的第 3 行( index 为 2 )。同理,对于单词 love ,相当于取出 embedding 矩阵的第二行( index 为 1 )。因此 embedding 矩阵的本质是一个查找表,每个单词会定位这个表中的某一行,而这一行就是这个单词学习到的在嵌入空间的语义。
首先准备所需要的数据,在 transformer 的解码器中,需要输入 n_batch * context_length * d_model 维度的 Tensor 数据,其中 n_batch 表示批次大小, contex_length 表示一次输入的单次数量, d_model 表示编码向量的长度。将 Tokenizer 中获得的 tokenized_text 进行数据预处理:
# Split train and validation | |
split_idx = int(len(tokenized_text) * 0.9) | |
train_data = tokenized_text[:split_idx] | |
val_data = tokenized_text[split_idx:] | |
# Get input embedding batch | |
data = train_data | |
idxs = torch.randint(low=0, high=len(data) - context_length, size=(batch_size,)) | |
x_batch = torch.stack([data[idx:idx + context_length] for idx in idxs]).to(device) | |
y_batch = torch.stack([data[idx + 1:idx + context_length + 1] for idx in idxs]).to(device) |
之后便可以利用 torch 中的 nn.Embedding 函数构造 Embedding 层。其中 Embedding.weight.data 是一个 max_token_value * d_model 维度的 Tensor 变量,是模型需要训练的参数,同时也是上图中对应的 Embedding 查找表。
# define input embedding table | |
# 获取 tokenized_text 中的最大值 + 1,用于构造 Embedding 的行 | |
max_token_value = tokenized_text.max().item() + 1 | |
# 使用 nn.Embedding 函数构造 Embedding 层 | |
# `Embedding.weight.data` 是一个 `max_token_value * d_model` 维度的 `Tensor` 变量 | |
token_embedding_lookup_table = nn.Embedding(num_embeddings=max_token_value, embedding_dim=d_model, device=device) | |
# 通过输入 x_batch 或 y_batch 即可获得对应的 Embedding 编码结果 | |
# x_batch_embedding 和 y_batch_embedding 是 `n_batch * context_length * d_model` 维度的 `Tensor` 数据 | |
x_batch_embedding = token_embedding_lookup_table(x_batch) | |
y_batch_embedding = token_embedding_lookup_table(y_batch) |
# 三、Position Encoding
在 transformer 的 encoder 和 decoder 的输入层中,均使用了 Positional Encoding ,使得最终的输入满足: input = input_embedding + positional_encoding 。
Transformer 位置编码的定义为:

实现位置编码的代码为:
# get positional encoding | |
position_encoding_lookup_table = torch.zeros(context_length, d_model).to(device) | |
# unsqueeze 用来扩充一个维度,为了后面的逐元素计算时的广播机制 | |
position = torch.arange(0, context_length, dtype=torch.float).unsqueeze(1).to(device) | |
# 根据公式计算位置编码 | |
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)).to(device) | |
position_encoding_lookup_table[:, 0::2] = torch.sin(position * div_term) | |
position_encoding_lookup_table[:, 1::2] = torch.cos(position * div_term) | |
# 将 context_length*d_model 的矩阵复制 n_epoch 次,形成 n_epoch*context_length*d_model 的矩阵 | |
position_encoding_lookup_table = position_encoding_lookup_table.unsqueeze(0).expand(batch_size, -1, -1) |
在获得位置编码之后即可将位置编码与 Embedding 进行相加,获得最终输入至网络的输入:
# add positional encoding to the input_embedding | |
x = x_batch_embedding + position_encoding_lookup_table | |
y = y_batch_embedding + position_encoding_lookup_table |
# 四、Transformer Block
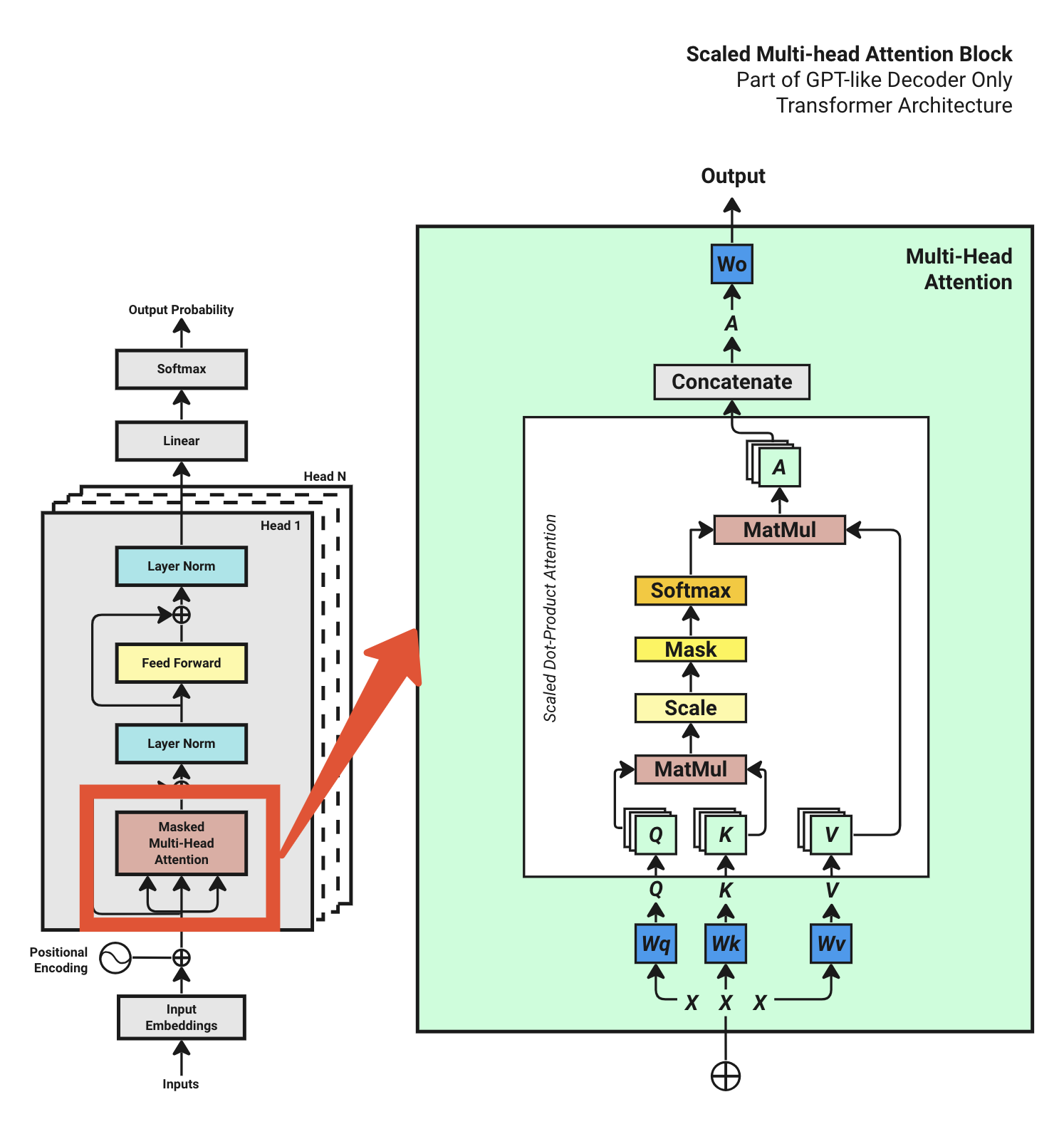
通过第三步,我们获得了输入 x ,下一步是开始实现多头注意力块( Muti-head Attention block )。
Transformer 模型的强大来源于 self-attention ,通过 self-attention , Transformer 模型可以关注到 input 更加重要的部分。
Multi-head attention 由几个单独的 heads 堆叠在一起组成。所有 heads 都接收到完全相同的输入,尽管它们在计算过程中使用了自己的特定权重集。在处理输入之后,来自所有 heads 的输出被级联,然后通过线性层。
heads 的工作方式是通过三个独特的层处理,即查询( Q )、键( K )和值( V )。 Attention 的计算公式可以从论文《 Attention is all you need 》中得到:
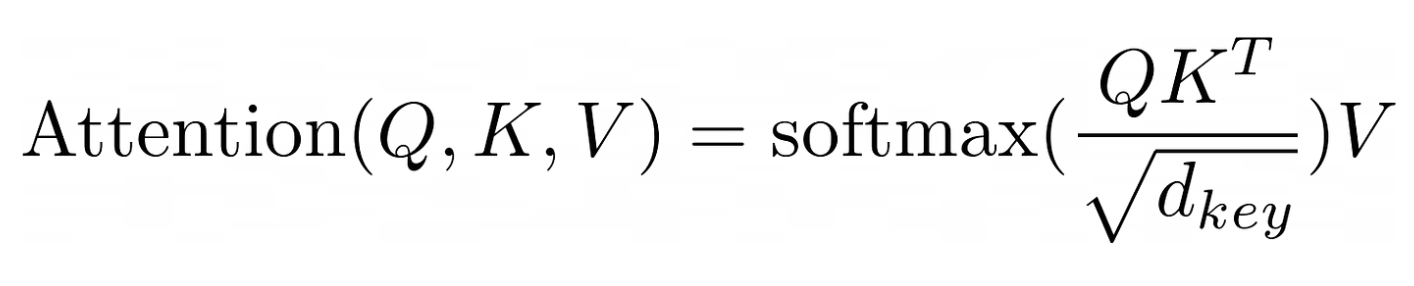
# get Q, K, V | |
# 所谓的多头就是把 d_model 切成多份,每一个头里面有一部分维度,然后去做这一部分的计算,最后再把所有的计算合并在一起 | |
head_size = d_model // num_heads # head size should be divisible by d_model | |
# (1) 计算 Q,K,V 矩阵 | |
key_layer = nn.Linear(in_features=d_model, out_features=d_model, bias=False, device=device) | |
query_layer = nn.Linear(in_features=d_model, out_features=d_model, bias=False, device=device) | |
value_layer = nn.Linear(in_features=d_model, out_features=d_model, bias=False, device=device) | |
# [batch_size, context_length, d_model] | |
q = query_layer(x) | |
k = key_layer(x) | |
v = value_layer(x) | |
# [batch_size, context_length, num_heads, head_size] | |
q = q.view(batch_size, -1, num_heads, head_size) | |
k = k.view(batch_size, -1, num_heads, head_size) | |
v = v.view(batch_size, -1, num_heads, head_size) | |
# [batch_size, num_heads, context_length, head_size] | |
q = q.transpose(1, 2) | |
k = k.transpose(1, 2) | |
v = v.transpose(1, 2) | |
# (2) 通过 Q @ K^T /sqrt (d_k) 计算 Attention | |
attention_score = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(head_size)) | |
# (3) 计算 Mask | |
mask = torch.triu(torch.ones(context_length, context_length), diagonal=1).bool().to(device) | |
attention_score = attention_score.masked_fill(mask, float('-inf')) | |
# (4) 计算 Softmax | |
# [batch_size, num_heads, context_length, context_length] | |
attention_score = F.softmax(attention_score, dim=-1) | |
# (5) 通过 $V 计算 A | |
# [batch_size, num_heads, context_length, head_size] | |
A = attention_score @ v | |
# (6) 计算 Concatenate | |
# [batch_size, context_length, num_heads, head_size] | |
A = A.transpose(1, 2) | |
# [batch_size, context_length, d_model] | |
A = A.reshape(batch_size, -1, d_model) | |
# (7) 通过 Wo 计算 Output | |
# Define the output weight matrix | |
Wo = nn.Linear(d_model, d_model) | |
# [batch_size, context_length, d_model] | |
output = Wo(A) |
# 五、Residual Connection and Layer Normalization
残差连接,有时被称为 skip connection ,是让原始输入 X 绕过一个或多个层的连接。通过将原始输入 x 与步骤四多头注意力层的输出 output 相加即可完成操作。
在残差连接之后,过程进入层归一化。层归一化( LayerNorm )是一种用于对网络中每一层的输出进行归一化的技术。其方法是减去输出的均值,并除以输出的标准差。使用这种技术是为了防止某一层的输出变得过大或过小,从而避免网络的不稳定性。
# Add residual connection | |
output = output + X | |
# Add Layer Normalization | |
layer_norm = nn.LayerNorm(d_model) | |
output = layer_norm(output) |
# 六、Feed-Forward Network
一旦我们获得了归一化的注意力权重(概率分数),它将被传递到一个位置级前馈网络中进行处理。前馈神经网络( FFN )由两个线性层和它们之间的 ReLU 激活函数组成。
# update x | |
x = output | |
# Define Feed Forward Network | |
output = nn.Linear(d_model, d_model * 4)(output) | |
output = nn.ReLU()(output) | |
output = nn.Linear(d_model * 4, d_model)(output) | |
output = torch.dropout(output, p=dropout, train=True) | |
# Add residual connection | |
output = output + x | |
# Add Layer Normalization | |
layer_norm = nn.LayerNorm(d_model) | |
output = layer_norm(output) |
# 七、Repeat step 4 to 6
以上我们完成的只是一个 transformer 块。在实际应用中,我们会将多个 transformer 块堆叠在一起,形成一个 transformer 解码器。
实际上,我们应该将代码封装到类中,并使用 PyTorch 的 nn.Module 来构建我们的 transformer 解码器。但为了演示,我们只使用一个块。
# 八、Output Probabilities
应用最后一个线性层来获得我们的 logits :
logits = nn.Linear(d_model, max_token_value)(output) |
最后一步是对逻辑回归输出进行 softmax 操作,以获得每个 token 的概率:
# torch.softmax usually used during inference, during training we use torch.nn.CrossEntropyLoss | |
# but for illustration purpose, we'll use torch.softmax here | |
probabilities = torch.softmax(logits, dim=-1) |
# Full Working Code
完整的代码可以参考 github : https://github.com/waylandzhang/Transformer-from-scratch
import os | |
import requests | |
import math | |
import tiktoken | |
import torch | |
import torch.nn as nn | |
from torch.nn import functional as F | |
# Hyperparameters | |
batch_size = 4 # How many batches per training step | |
context_length = 16 # Length of the token chunk each batch | |
d_model = 64 # The size of our model token embeddings | |
num_blocks = 8 # Number of transformer blocks | |
num_heads = 4 # Number of heads in Multi-head attention | |
learning_rate = 1e-3 # 0.001 | |
dropout = 0.1 # Dropout rate | |
max_iters = 5000 # Total of training iterations <- Change this to smaller number for testing | |
eval_interval = 50 # How often to evaluate | |
eval_iters = 20 # Number of iterations to average for evaluation | |
device = 'cuda' if torch.cuda.is_available() else 'cpu' # Use GPU if it's available. | |
TORCH_SEED = 1337 | |
torch.manual_seed(TORCH_SEED) | |
# Load training data | |
if not os.path.exists('data/sales_textbook.txt'): | |
url = 'https://huggingface.co/datasets/goendalf666/sales-textbook_for_convincing_and_selling/raw/main/sales_textbook.txt' | |
with open('data/sales_textbook.txt', 'w') as f: | |
f.write(requests.get(url).text) | |
with open('data/sales_textbook.txt', 'r', encoding='utf-8') as f: | |
text = f.read() | |
# Using TikToken (Same as GPT3) to tokenize the source text | |
encoding = tiktoken.get_encoding("cl100k_base") | |
tokenized_text = encoding.encode(text) | |
max_token_value = max(tokenized_text) + 1 # the maximum value of the tokenized numbers | |
tokenized_text = torch.tensor(tokenized_text, dtype=torch.long, device=device) # put tokenized text into tensor | |
# Split train and validation | |
split_idx = int(len(tokenized_text) * 0.9) | |
train_data = tokenized_text[:split_idx] | |
val_data = tokenized_text[split_idx:] | |
# Define Feed Forward Network | |
class FeedForward(nn.Module): | |
def __init__(self): | |
super().__init__() | |
self.d_model = d_model | |
self.dropout = dropout | |
self.ffn = nn.Sequential( | |
nn.Linear(in_features=self.d_model, out_features=self.d_model * 4), | |
nn.ReLU(), | |
nn.Linear(in_features=self.d_model * 4, out_features=self.d_model), | |
nn.Dropout(dropout), | |
) | |
def forward(self, x): | |
return self.ffn(x) | |
# Define Scaled Dot Product Attention | |
class Attention(nn.Module): | |
def __init__(self, head_size: int): | |
super().__init__() | |
self.d_model = d_model | |
self.head_size = head_size | |
self.context_length = context_length | |
self.dropout = dropout | |
self.key_layer = nn.Linear(in_features=self.d_model, out_features=self.head_size, bias=False) | |
self.query_layer = nn.Linear(in_features=self.d_model, out_features=self.head_size, bias=False) | |
self.value_layer = nn.Linear(in_features=self.d_model, out_features=self.head_size, bias=False) | |
self.register_buffer('tril', torch.tril( | |
torch.ones((self.context_length, self.context_length)))) # Lower triangular mask | |
self.dropout_layer = nn.Dropout(self.dropout) | |
def forward(self, x): | |
B, T, C = x.shape # Batch size, Time steps(current context_length), Channels(dimensions) | |
assert T <= self.context_length | |
assert C == self.d_model | |
q = self.query_layer(x) | |
k = self.key_layer(x) | |
v = self.value_layer(x) | |
# Scaled dot product attention: Q @ K^T / sqrt(d_k) | |
weights = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1))) | |
# Apply masked attention | |
weights = weights.masked_fill(self.tril[:T, :T] == 0, float('-inf')) | |
weights = F.softmax(input=weights, dim=-1) | |
weights = self.dropout_layer(weights) | |
# Apply dot product attention: weights @ V | |
out = weights @ v | |
return out | |
class MultiHeadAttention(nn.Module): | |
def __init__(self, head_size: int): | |
super().__init__() | |
self.num_heads = num_heads | |
self.head_size = head_size | |
self.d_model = d_model | |
self.context_length = context_length | |
self.dropout = dropout | |
self.heads = nn.ModuleList([Attention(head_size=self.head_size) for _ in range(self.num_heads)]) | |
self.projection_layer = nn.Linear(in_features=self.d_model, out_features=self.d_model) | |
self.dropout_layer = nn.Dropout(dropout) | |
def forward(self, x): | |
out = torch.cat([h(x) for h in self.heads], dim=-1) | |
out = self.projection_layer(out) | |
out = self.dropout_layer(out) | |
return out | |
class TransformerBlock(nn.Module): | |
def __init__(self, num_heads: int): | |
super().__init__() | |
self.d_model = d_model | |
self.context_length = context_length | |
self.head_size = d_model // num_heads # head size should be divisible by d_model | |
self.num_heads = num_heads | |
self.dropout = dropout | |
self.multi_head_attention_layer = MultiHeadAttention(head_size=self.head_size) | |
self.feed_forward_layer = FeedForward() | |
self.layer_norm_1 = nn.LayerNorm(normalized_shape=self.d_model) | |
self.layer_norm_2 = nn.LayerNorm(normalized_shape=self.d_model) | |
def forward(self, x): | |
# Note: The order of the operations is different from the original Transformer paper | |
# The order here is: LayerNorm -> Multi-head attention -> LayerNorm -> Feed forward | |
x = x + self.multi_head_attention_layer(self.layer_norm_1(x)) # Residual connection | |
x = x + self.feed_forward_layer(self.layer_norm_2(x)) # Residual connection | |
return x | |
class TransformerLanguageModel(nn.Module): | |
def __init__(self): | |
super().__init__() | |
self.d_model = d_model | |
self.context_length = context_length | |
self.num_heads = num_heads | |
self.num_blocks = num_blocks | |
self.dropout = dropout | |
self.max_token_value = max_token_value | |
# Set up token embedding look-up table | |
self.token_embedding_lookup_table = nn.Embedding(num_embeddings=self.max_token_value + 1, embedding_dim=self.d_model) | |
# Run all the transformer blocks | |
# Different from original paper, here we add a final layer norm after all the blocks | |
self.transformer_blocks = nn.Sequential(*( | |
[TransformerBlock(num_heads=self.num_heads) for _ in range(self.num_blocks)] + | |
[nn.LayerNorm(self.d_model)] | |
)) | |
self.language_model_out_linear_layer = nn.Linear(in_features=self.d_model, out_features=self.max_token_value) | |
def forward(self, idx, targets=None): | |
B, T = idx.shape | |
""" | |
# Set up position embedding look-up table | |
# following the same approach as the original Transformer paper (Sine and Cosine functions) | |
""" | |
position_encoding_lookup_table = torch.zeros(self.context_length, self.d_model) | |
position = torch.arange(0, self.context_length, dtype=torch.float).unsqueeze(1) | |
div_term = torch.exp(torch.arange(0, self.d_model, 2).float() * (-math.log(10000.0) / self.d_model)) | |
position_encoding_lookup_table[:, 0::2] = torch.sin(position * div_term) | |
position_encoding_lookup_table[:, 1::2] = torch.cos(position * div_term) | |
# change position_encoding_lookup_table from (context_length, d_model) to (T, d_model) | |
position_embedding = position_encoding_lookup_table[:T, :].to(device) | |
x = self.token_embedding_lookup_table(idx) + position_embedding | |
x = self.transformer_blocks(x) | |
# The "logits" are the output values of our model before applying softmax | |
logits = self.language_model_out_linear_layer(x) | |
if targets is not None: | |
B, T, C = logits.shape | |
logits_reshaped = logits.view(B * T, C) | |
targets_reshaped = targets.view(B * T) | |
loss = F.cross_entropy(input=logits_reshaped, target=targets_reshaped) | |
else: | |
loss = None | |
return logits, loss | |
def generate(self, idx, max_new_tokens): | |
# idx is (B,T) array of indices in the current context | |
for _ in range(max_new_tokens): | |
# Crop idx to the max size of our positional embeddings table | |
idx_crop = idx[:, -self.context_length:] | |
# Get predictions | |
logits, loss = self(idx_crop) | |
# Get the last time step from logits where the dimensions of the logits are (B,T,C) | |
logits_last_timestep = logits[:, -1, :] | |
# Apply softmax to get probabilities | |
probs = F.softmax(input=logits_last_timestep, dim=-1) | |
# Sample from the probabilities' distribution. | |
idx_next = torch.multinomial(input=probs, num_samples=1) | |
# Append the sampled indexes idx_next to idx | |
idx = torch.cat((idx, idx_next), dim=1) | |
return idx | |
# Initialize the model | |
model = TransformerLanguageModel() | |
model = model.to(device) | |
# Get input embedding batch | |
def get_batch(split: str): | |
data = train_data if split == 'train' else val_data | |
idxs = torch.randint(low=0, high=len(data) - context_length, size=(batch_size,)) | |
x = torch.stack([data[idx:idx + context_length] for idx in idxs]).to(device) | |
y = torch.stack([data[idx + 1:idx + context_length + 1] for idx in idxs]).to(device) | |
return x, y | |
# Calculate loss | |
@torch.no_grad() | |
def estimate_loss(): | |
out = {} | |
model.eval() | |
for split in ['train', 'valid']: | |
losses = torch.zeros(eval_iters) | |
for k in range(eval_iters): | |
x_batch, y_batch = get_batch(split) | |
logits, loss = model(x_batch, y_batch) | |
losses[k] = loss.item() | |
out[split] = losses.mean() | |
model.train() | |
return out | |
# Use AdamW optimizer | |
optimizer = torch.optim.AdamW(params=model.parameters(), lr=learning_rate) | |
tracked_losses = list() | |
for step in range(max_iters): | |
if step % eval_iters == 0 or step == max_iters - 1: | |
losses = estimate_loss() | |
tracked_losses.append(losses) | |
print('Step:', step, 'Training Loss:', round(losses['train'].item(), 3), 'Validation Loss:', | |
round(losses['valid'].item(), 3)) | |
xb, yb = get_batch('train') | |
logits, loss = model(xb, yb) | |
optimizer.zero_grad(set_to_none=True) | |
loss.backward() | |
optimizer.step() | |
# Save the model state dictionary | |
torch.save(model.state_dict(), 'model-ckpt.pt') | |
# Generate | |
model.eval() | |
start = 'The salesperson' | |
start_ids = encoding.encode(start) | |
x = (torch.tensor(start_ids, dtype=torch.long, device=device)[None, ...]) | |
y = model.generate(x, max_new_tokens=100) | |
print('---------------') | |
print(encoding.decode(y[0].tolist())) | |
print('---------------') |