参考链接:https://blog.csdn.net/DFCED/article/details/132394895、https://www.bilibili.com/video/BV1QAexeiEZK?p=2&vd_source=e01172ea292c1c605b346101d7006c61
扩散概率模型(为简洁起见,我们称之为 “扩散模型”)是一种通过参数化的马尔科夫链,并使用变分推断进行训练,以在有限时间后生成与数据相匹配的样本。该链的转换过程旨在学习逆向扩散过程,即一个马尔科夫链,该链逐步向数据中添加噪声,方向与采样相反,直到信号完全被破坏。
# 一、直观理解
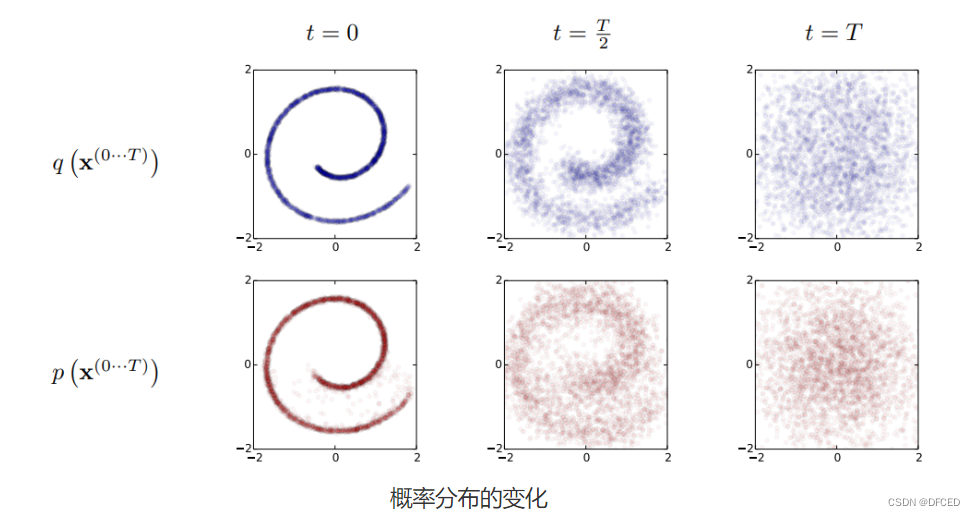
从概率分布角度来看,考虑下图瑞士卷形状的二维联合概率分布 P (x,y),扩散过程 q 非常直观,本来集中有序的样本点,受到噪声的扰动,向外扩散,最终变成一个完全无序的噪声分布。
![]()
而 diffusion model 表示上图的逆过程 p,将一个噪声分布 N (0,1) 逐步的去噪以映射到原始图像。有了这样的映射,就可以从噪声分布中采样,最终得到一张想要的图像,也就是完成了生成的任务。
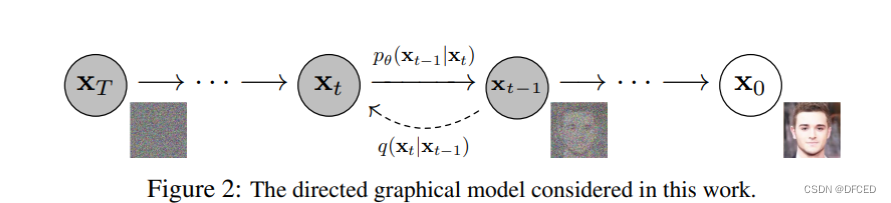
Diffusion Models 由正向过程(或扩散过程)和反向过程(或逆扩散过程)组成,其中输入数据逐渐被噪声化,然后噪声被转换回源目标分布的样本。从单个图像样本来看这个过程,扩散过程 q 就是不断向图像上加噪声,直到图像变成一个纯噪声,逆扩散过程 p 就是从纯噪声生成一张图像的过程。下图表示了单个样本图像的变化:
![]()
一些相关的概念:
- 后验概率:在贝叶斯统计中,一个随机事件或者一个不确定事件的后验概率(Posterior probability)是在考虑和给出相关证据或数据后所得到的条件概率。
- 马尔可夫链:为状态空间中经过从一个状态到另一个状态的转换的随机过程。该过程要求具备 “无记忆” 的性质:下一状态的概率分布只能由当前状态决定,在时间序列中它前面的事件均与之无关。这种特定类型的 “无记忆性 “称作马可夫性质。
# 二、前向过程(扩散过程)
所谓前向过程,即往图片上加噪声的过程。虽然这个步骤无法做到图片生成,但是这是理解 diffusion model 以及构建训练样本至关重要的一步。
给定真实图片样本 x0∼q(x),diffusion 前向过程通过T 次累计对其添加高斯噪声,得到x1,x2,…,xT,如下图的 q 过程。每一步的大小是由一系列的高斯分布方差的超参数{βt∈(0,1)}t=1T 来控制的。前向过程由于每个时刻t 只与t−1 时刻有关,所以也可以看做马尔科夫过程:
q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)
q(x1:T∣x0)=t=1∏Tq(xt∣xt−1)
这个过程中,随着t 的增大,xt 越来越接近纯噪声。当T⇒∞,xT 是完全的高斯噪声。
前向过程介绍结束前,需要讲述一下 diffusion 在实现和推导过程中要用到的两个重要特性。
- 特性 1:重参数 (reparameterization trick)
重参数技巧在很多工作(gumbel softmax, VAE)中有所引用。如果我们要从某个分布中随机采样(高斯分布)一个样本,这个过程是无法反传梯度的。而这个通过高斯噪声采样得到xt 的过程在 diffusion 中到处都是,因此我们需要通过重参数技巧来使得他可微。最通常的做法是把随机性通过一个独立的随机变量($\epsilon )引导过去。即如果要从高斯分布 z\sim\mathcalN}(z;\mu_\theta,\sigma_\theta)采样一个 z$,我们可以写成:
z=μθ+σθ⊙ϵ,ϵ∼N(0,I)
上式的z 依旧是有随机性的,且满足均值为μθ 方差为σθ 的高斯分布。这里的μθ,σθ 可以是由神经网络推断得到的。整个 “采样” 过程依旧梯度可导,随机性被转嫁到了 $\epsilon $ 上。
- 特征 2:任意时刻的xt 可由x0 和βt 表示
在前向过程中,有一个性质非常棒,就是我们其实可以通过x0 和βt 直接得到xt。首先我们令αt=1−βt,并且αt=∏i=1tαi,展开xt 可以得到:
xt=αtxt−1+1−αtϵt−1=αtαt−1xt−2+1−αtαt−1ϵˉt−2=…=αˉtx0+1−αˉtϵ
因此,任意时刻的xt 满足:
q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I)
# 三、反向过程(逆扩散过程)
如果说前向过程(forward)是加噪的过程,那么逆向过程(reverse) 就是 diffusion 的去噪推断过程。
如果我们能够逆转上述过程并从q(xt−1∣xt) 采样,就可以从高斯噪声xT∼N(0,I) 还原出原图分布x0∼q(x)。在文献 7 中证明了如果q(xt∣xt−1) 满足高斯分布且βt 足够小,q(xt−1∣xt) 仍然是一个高斯分布。然而我们无法简单推断q(xt−1∣xt),因此我们使用深度学习模型(参数力θ,目前主流是 U-Net + attention 的结构)去预测这样的一个逆向的分布pθ(类似 VAE):
pθ(x0:T)=p(xT)t=1∏Tpθ(xt−1∣xt);
pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t)).
由此可以发现其实正向扩散和逆扩散过程都是马尔可夫,然后正态分布,然后一步一步条件概率的框架。唯一的区别就是正向扩散里每一个条件概率的高斯分布的均值和方差都是
已经确定的(依赖于βt 和x0),而逆扩散过程里面的均值和方差是我们网络要学出来。
# 逆扩散条件概率推导
虽然我们无法得到逆转过程的概率分布q(xt−1∣xt),但是如果知道x0,q(xt−1∣xt,x0) 就可以直接写出,大概形式如下:
q(xt−1∣xt,x0)=N(xt−1;μ~(xt,x0),β~tI)
通过一定的计算可以得到上式中的均值和方差为:
β~t=1−αˉt1−αˉt−1⋅βt
μ~t=αt1(xt−1−αt1−αtϵt)
可以看出,在给定x0 的条件下,后验条件高斯分布的均值只和超参数,xt,ϵ 有关,方差只与超参数有关。
# 四、训练损失
了解了上述逆扩散过程之后,如何训练 Diffusion Models 以求得后验条件高斯分布的均值μθ(xt,t) 和方差Σθ(xt,t) 呢?
对于真实的训练样本数据已知,要求模型的参数,可以使用极大似然估计。Diffusion Models 通过极大似然估计,来找到逆扩散过程中马尔可夫链转换的概率分布,这就是 Diffusion Models 的训练目的。即最大化模型预测分布的对数似然,从 Loss 下降的角度就是最小化负对数似然:
L=Eq[−logpθ(x0)]
通过一定的推导可以得到如下损失函数:
Lt=Ex0,ϵ[∥∥∥∥∥αt1(xt−1−αˉtβtϵ)−αt1(xt−1−αˉtβtϵθ(xt,t))∥∥∥∥∥2]ϵ∼N(0,1)=Ex0,ϵ[∥ϵ−ϵθ(xt,t)∥2]ϵ∼N(0,1)=Ex0,ϵ[∥∥∥ϵ−ϵθ(αtx0+1−αtϵ,t)∥∥∥2],ϵ∼N(0,1)
经过这样一番推导之后就是个 L2-loss。网络的输入是一张和噪声线性组合的图片,然后要估计出来这个噪声。
ϵθ(αtx0+1−αtϵ,t)
# 五、训练过程
![]()
训练过程如上图左边 Algorithm 1 Training 部分:
- 从标准高斯分布采样一个噪声ϵ∼N(0,I);
- 通过梯度下降最小化损失∇θ∣ϵ−zθ(αˉtx0+1−αˉtϵ,t)∣2;
- 训练到收敛为止;
测试(采样)如上图右边 Algorithm 2 Sampling 部分:
- 从标准高斯分布采样一个噪声xT∼N(0,I);
- 从时间步 T 开始正向扩散迭代到时间步 1;
- 如果时间步不为 1,则从标准高斯分布采样一个噪声z∼N(0,I),否则z=0;
- 根据高斯分布计算每个时间步t 的噪声图;
# 六、代码实现
参考文章:https://www.assemblyai.com/blog/diffusion-models-for-machine-learning-introduction/
| import torch |
| from denoising_diffusion_pytorch import Unet, GaussianDiffusion |
| |
| model = Unet( |
| dim = 64, |
| dim_mults = (1, 2, 4, 8) |
| ).cuda() |
| |
| diffusion = GaussianDiffusion( |
| model, |
| image_size = 128, |
| timesteps = 1000, |
| loss_type = 'l1' |
| ).cuda() |
| |
| |
| training_images = torch.randn(8, 3, 128, 128) |
| loss = diffusion(training_images) |
| loss.backward() |
| |
| sampled_images = diffusion.sample(batch_size = 4) |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |