# 一、简介
# 1.1 前言
CLIP 是 OpenAI 在 2021 年 2 月发表的一篇文章,其全称为 Contrastive Language-Image Pre-training ,即一种基于对比文本 - 图像对的预训练方法。 CLIP 用文本作为监督信号来训练可迁移的视觉模型,使得最终模型的 zero-shot 效果堪比 ResNet50 ,泛化性非常好。
zero-shot 就是直接推理,用见过的图片特征去判断没见过的图片的类别,而完全不用下游任务训练集进行微调。(相当于把模型用作特征提取,但是没有分类头)
作者在 30 多个不同的计算机视觉数据集上进行基准测试,(这些数据集涵盖了 OCR ( Optical Character Recognition , 光学字符识别)、视频中的动作识别、地理定位和许多类型的细粒度对象分类等任务), CLIP 通常都能够与监督模型的 baseline 效果相媲美。
例如在 ImageNet 数据集上, CLIP 模型在不使用 ImageNet 数据集的任何一张图片进行训练的的情况下,最终模型精度能跟一个有监督的训练好的 ResNet-50 打成平手(在 ImageNet 上 zero-shot 精度为 76.2% ,这在之前一度被认为是不可能的)。
# 1.2 自然语言监督的优势
使用自然语言监督信号来训练视觉模型,有两个最重要的优势:
-
不需要采用特别的标注数据,扩展性更强。比如
ImageNet需要先定义好1000个类,然后根据这些类去下载图片,清理数据集,再去标注所有图片,过程很复杂。而 CLIP 不要求这种经典的 "机器学习兼容" 的标注格式,只需要下载文字 - 图片对;且没有 n 选 1 的标签之后,模型的输入输出自由度大了很多。 -
CLIP学习到的是图像结合文字的多模态特征,从而实现灵活的 zero-shot 迁移。如果只是单模态的特征,无论是类似MOCO还是MAE,都很难做到这一点(zero-shot必须要加入文字特征才能做到)。
# 1.3 总结
现有的 CV 模型基本都是基于人工标注的数据集进行训练的,然后用来预测一组提前定义好的物体类别。这种提前定义好的标签集合,会大大简化问题本身(比如 ImageNet 固定的 1000 个类, COCO 数据集固定 80 个类等等)。但正因如此,这种受限的监督信号限制了模型的泛化性和可用性。比如大多数模型都只能预测已知的图像类别。对于没有见过的图像类别,需要额外的信息才能识别。这样每次新增一些类别,都需要重新收集数据,训练一个新的模型。
作者认为,直接从自然语言中得到监督信息是一个很有前途的选择,因为其涵盖的范围更广(只要是语言描述过的物体,都有可能让视觉模型去识别)。 CLIP 利用多模态的对比学习,使得自然语言可以引导模型学习到视觉概念,从而实现非常灵活的 zero-shot 迁移(把分类问题转化为了跨模态检索问题)。
之前使用自然语言监督进行图像表示学习的工作很少,并且效果往往不如有监督模型,主要有两个原因:
- 早期 nlp 模型不太好学。比如早期的
n-gram模型非常复杂,不好跨模态训练。但是随着transformer的兴起,像BERT和GPT这种具有上下文表示的自监督训练模型做的越来越好,nlp模型也终于有了取之不尽的文本监督信号,而且使用简单,泛化性好,为多模态训练铺平了道路。 - 数据集或模型的规模不够。比如
VirTex和ICMLM都只训练了十几万的图片;ConVIRT非常类似CLIP,但只在医疗图像上做了预训练。从本质上来讲,CLIP其实并没有太大的创新,它只是将 ConVIRT 方法进行简化,并采用更大规模的文本 - 图像对数据集来训练。也可以说,相对于之前的对比学习,CLIP只是将单模态的样本,换成了多模态的样本。
# 二、方法
# 2.1 模型结构
如下图所示, CLIP 的输入是一对对配对好的的图片 - 文本对(比如输入是一张狗的图片,对应文本也表示这是一只狗)。这些文本和图片分别通过 Text Encoder 和 Image Encoder 输出对应的特征。然后在这些输出的文字特征和图片特征上进行对比学习。
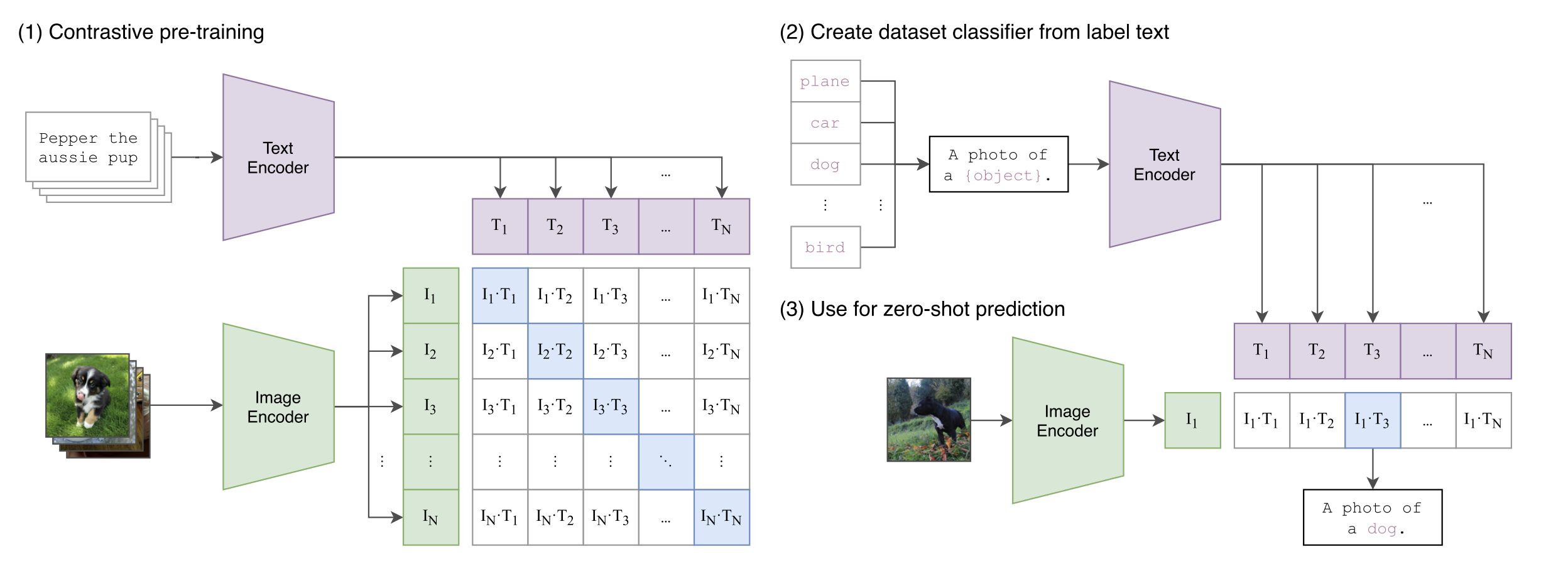
假如模型输入的是 对图片 - 文本对,那么这 对互相配对的图像–文本对是正样本(下图输出特征矩阵对角线上标识蓝色的部位),其它 对样本都是负样本。这样模型的训练过程就是最大化 个正样本的相似度,同时最小化 个负样本的相似度。
其中:
-
Text Encoder可以采用NLP中常用的text transformer模型;而Image Encoder可以采用常用CNN模型或者vision transformer等模型 -
相似度是计算文本特征和图像特征的余弦相似性
cosine similarity -
为了训练
CLIP,OpenAI从互联网收集了共 4 个亿的文本 - 图像对,论文称之为WIT(Web Image Text)。WIT质量很高,而且清理的非常好,其规模相当于JFT-300M,这也是CLIP如此强大的原因之一(后续在WIT上还孕育出了DALL-E模型)
分类
CLIP 可以直接实现 zero-shot 的图像分类,即不需要任何训练和微调,这也是 CLIP 亮点和强大之处。用 CLIP 实现 zero-shot 分类只需要简单的两步:
-
根据任务的分类标签构建每个类别的描述文本:
A photo of {label},然后将这些文本送入Text Encoder得到对应的文本特征。如果类别数目为,那么将得到 个文本特征; -
将要预测的图像送入
Image Encoder得到图像特征,然后与 个文本特征计算缩放的余弦相似度(和训练过程保持一致),然后选择相似度最大的文本对应的类别作为图像分类预测结果。进一步地,可以将这些相似度看成logits,送入softmax后可以到每个类别的预测概率。
我们不再需要预先定义好的标签(类别)列表,直接将图片喂给不同的文本句子,就可以知道图片中是否有我们感兴趣的物体。即, CLIP 的多模态特性(利用文本监督信号)为具体的任务构建了动态的分类器,使得模型不再受限于预先定义好的类别,更加具有通用性和可用性。
# 2.2 预训练方法
CV 领域的模型都很大,训练起来也很贵。比如 noise student 之前在 ImageNet 一直霸榜,但是这个模型需要在一个 TPUv3 上训练 33 年,这还只是在包含 1000 类的 ImageNet 上预训练的,而且只训练视觉特征。
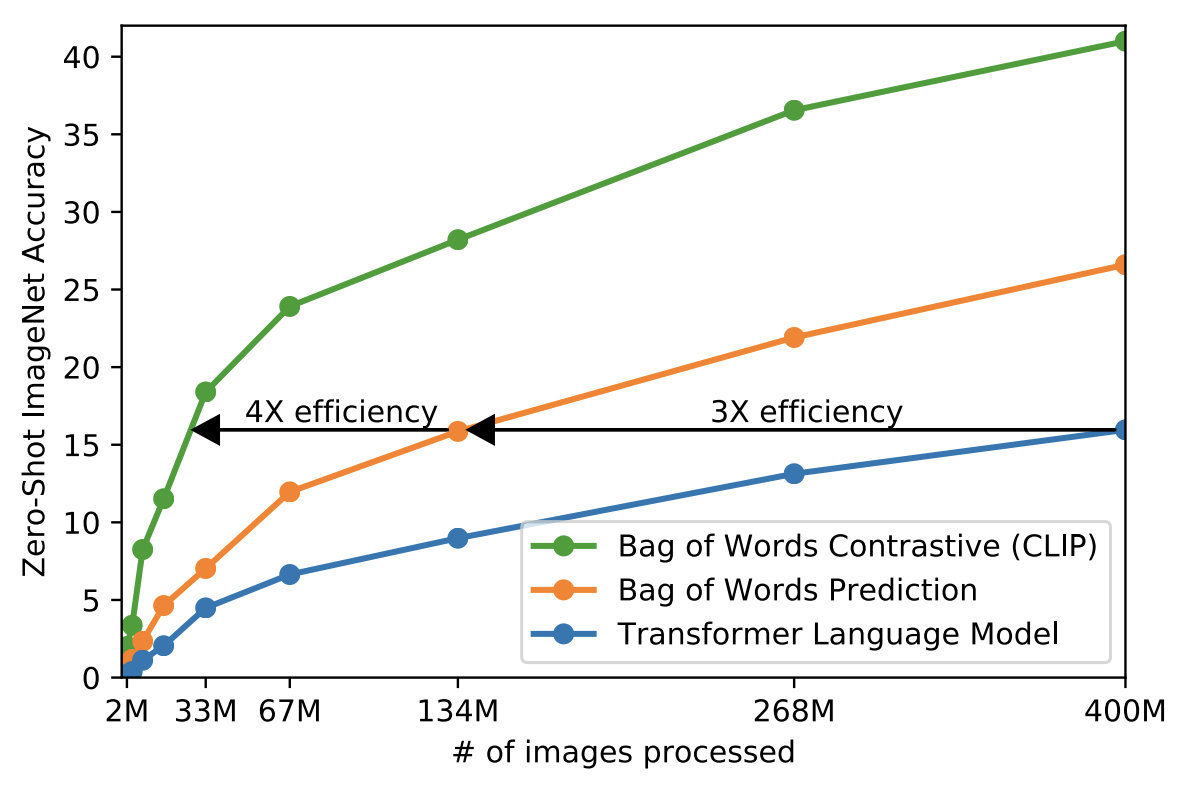
由于训练数据量和模型计算量都很大,训练效率成为一个至关重要的因素。作者做了很多尝试,最终选择了对比学习:
-
VirTex模型:预测文本,对应下图蓝色线Transformer Language Model:Image Encoder使用CNN模型,Text Encoder使用transformer模型,两个模型一起从头训练,任务是预测图片对应的文本(image caption)。这种方法的训练效率太慢,因为根据图片进行文本描述,可能性太多了,你可以从各个角度去描述一张图片。 -
Bag of Words Prediction(橘色线):不要求每个词都是按顺序的进行预测,所有词都预测出来就行。这样放宽了约束,训练速度提高了三倍。 -
CLIP:简化版的ConVIRT,基于对比学习。只需要判断图文是否配对,进一步简化了训练任务,训练效率一下子提升4倍(绿色线)训练任务更加合理。因为训练数据所包含的文本 - 图像对是从互联网收集来的,它们存在一定的噪音,二者并不完全匹配。适当的降低训练目标,反而能取得更好的收敛。
(1) Text Encoder 架构
最终 Text Encoder 固定选择一个包含 63M 参数的 text transformer 模型,
(2) Image Encoder 架构
-
ResNet:ResNet50,ResNet101,RN50x4,RN50x16和RNx64(后面三个模型是按照EfficientNet缩放规则对ResNet分别增大4x,16x和64x得到) -
ViT:ViT-B/32,ViT-B/16和ViT-L/14。
(3) 所有的模型都训练 32 个 epochs,采用 AdamW 优化器,batch size=32768
(4) 只在 ResNet50 上训练一个 epoch 进行超参搜索,没有进行进一步的调参
(5) 数据集非常大,几乎不会出现过拟合,所以 Image Encoder 和 Text Encoder 不需要提前进行预训练。
(6) 只使用线性投射层(线性非线性影响不大)
(7) 数据增强只使用图片的随机剪裁,这是因为数据集非常大
(8) 对比学习目标函数中的超参数 τ,设置成可学习的标量,在训练中自动优化,而不用慢慢调参(还是因为数据集太大,训练很贵)。
# 2.3 伪代码
# image_encoder - ResNet or Vision Transformer | |
# text_encoder - CBOW or Text Transformer | |
# I [n, h, w, c] - 输入图片维度 | |
# T [n, l] - 输入文本维度,l 表示序列长度 | |
# W_i[d_i, d_e] - learned proj of image to embed | |
# W_t[d_t, d_e] - learned proj of text to embed | |
# t - learned temperature parameter | |
# 分别提取图像特征和文本特征 | |
I_f = image_encoder(I) #[n, d_i] | |
T_f = text_encoder(T) #[n, d_t] | |
# 对两个特征进行线性投射,得到相同维度的特征 d_e,并进行 l2 归一化,保持数据尺度的一致性 | |
# 多模态 embedding [n, d_e] | |
I_e = l2_normalize(np.dot(I_f, W_i), axis=1) | |
T_e = l2_normalize(np.dot(T_f, W_t), axis=1) | |
# 计算缩放的余弦相似度:[n, n] | |
logits = np.dot(I_e, T_e.T) * np.exp(t) | |
# symmetric loss function | |
labels = np.arange(n) # 对角线元素的 labels | |
loss_i = cross_entropy_loss(logits, labels, axis=0) # image loss | |
loss_t = cross_entropy_loss(logits, labels, axis=1) # text loss | |
loss = (loss_i + loss_t)/2 # 对称式的目标函数 |
在 MOCO 中,真实标签都是 0 ,因为其正样本都是放在第一位,所以正样本对应的索引永远是 0 ;但是在 CLIP 中,正样本都是在对角线上,即,所以真实标签为 np.arange(n) 。
# 三、参考程序
参考:https://huggingface.co/openai/clip-vit-large-patch14
from PIL import Image | |
from transformers import CLIPProcessor, CLIPModel | |
model = CLIPModel.from_pretrained("E:/python/else/LLM_learn/4_CLIP/model") | |
processor = CLIPProcessor.from_pretrained("E:/python/else/LLM_learn/4_CLIP/model") | |
image = Image.open('1.jpg') | |
inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True) | |
outputs = model(**inputs) | |
logits_per_image = outputs.logits_per_image # this is the image-text similarity score | |
print(logits_per_image) | |
probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities | |
print(probs) |