# 一、引言
BERT ( Bidirectional Encoder Representations from Transformers )是一种基于深度学习的自然语言处理( NLP )模型。它是由 Google 在 2018 年提出的,采用了 Transformer 架构,并在大规模语料库上进行了预训练。 BERT 的特点之一是其双向( Bidirectional )处理能力,它能够同时考虑到句子中所有单词的上下文,而不仅仅是单词之前或之后的部分。这种双向性使得 BERT 在许多 NLP 任务中表现出色,例如文本分类、问答和命名实体识别等。
# 二、BERT
BERT 的框架中有两个步骤:预训练和微调。在预训练过程中,模型在不同的预训练任务上对未标记数据进行训练。对于微调,首先使用预训练的参数初始化 BERT 模型,然后使用来自下游任务的标记数据对所有参数进行微调。每个下游任务都有单独的微调模型,即使它们是用相同的预训练参数初始化的。
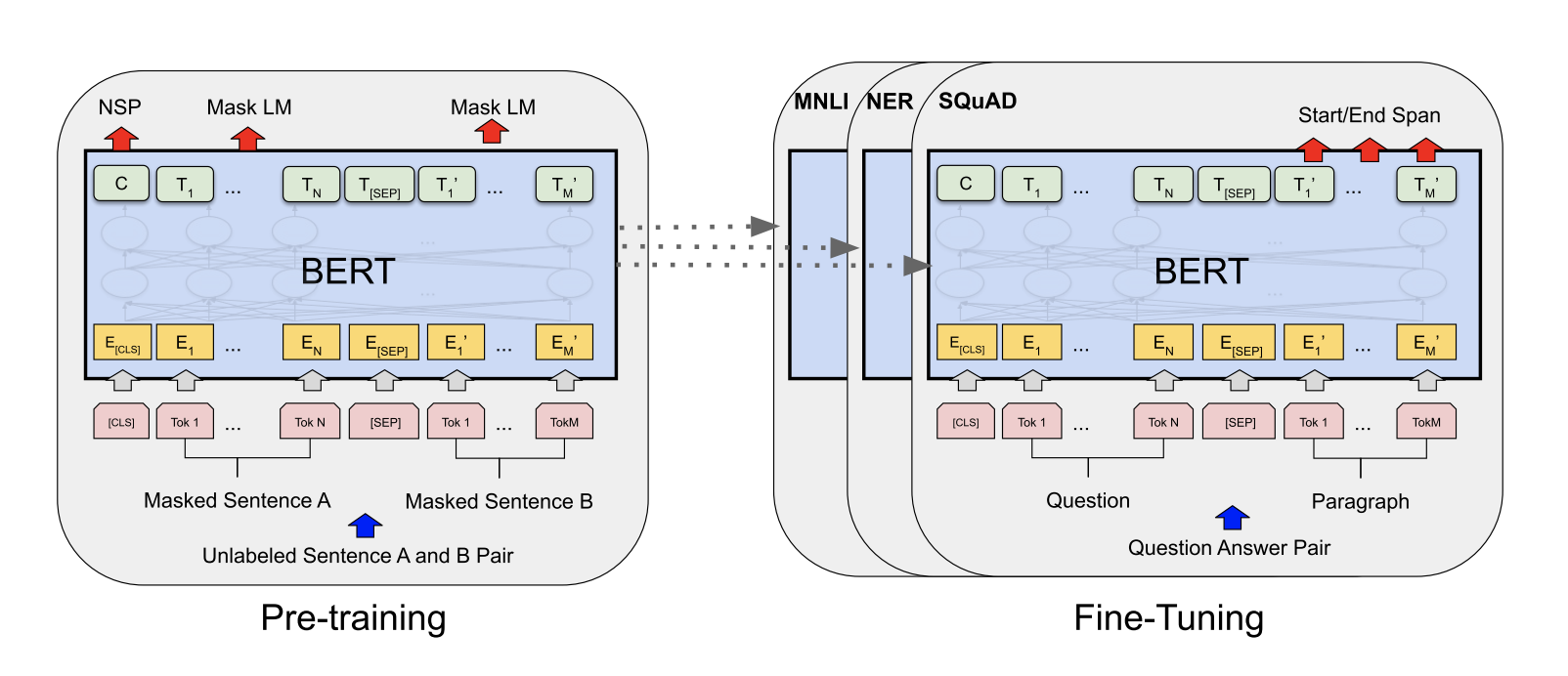
BERT 的一个显著特征是其跨不同任务的统一架构。预训练的体系结构和最终的下游体系结构之间的差别很小。除了输出层,在预训练和微调中使用了相同的架构。使用相同的预训练模型参数来初始化不同下游任务的模型。在微调期间,对所有参数进行微调。[CLS] 是添加在每个输入示例前面的特殊符号,[SEP] 是一个特殊的分隔符号 (例如,分隔问题 / 答案)。
# 2.1 模型结构
BERT 的模型架构是一个多层双向 transformer 编码器,使用 表示层数 (即 transformer 块),隐藏大小为,自注意头的数量为。 BERT 主要有两种模型大小: BERT BASE (L=12, H=768, A=12, Total Parameters=110M) 和 BERT LARGE (L=24, H=1024, A=16, Total Parameters=340M)。
为了进行比较,选择 BERT BASE 与 OpenAI GPT 具有相同的模型大小。然而,关键的是, BERT Transformer 使用双向自关注,而 GPT Transformer 使用约束自关注,其中每个 token 只能关注其左侧的上下文。
# 2.2 输入 / 输出表示
为了使 BERT 处理各种下游任务,我们的输入表示能够在一个 token 序列中明确地表示单个句子和一对句子 (例如,<Question, Answer>)。在整个工作中,一个 “句子” 可以是一个连续文本的任意跨度,而不是一个实际的语言句子。“序列” 指的是 BERT 的输入 token 序列,它可以是一个句子或两个句子组合在一起。
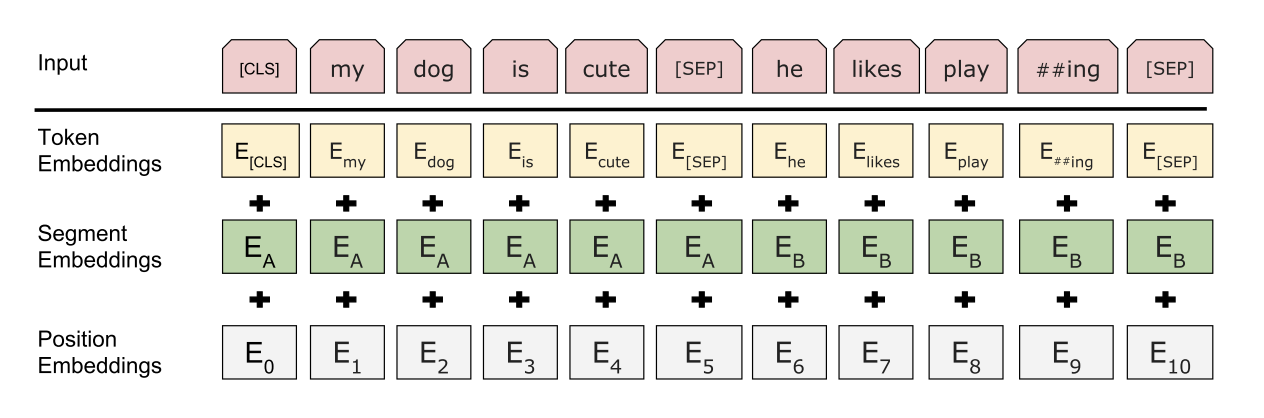
BERT 使用具有 30,000 个词汇的 WordPiece embeddings 。每个序列的第一个标记总是一个特殊的分类标记 ([CLS])。 BERT 用两种方法区分句子。首先,用一个特殊的 token ([SEP]) 将它们分开。其次,为每一个 token 添加一个可学习 embedding ,表明它属于句子 A 还是句子 B 。如图 1 所示,将输入 embedding 表示为,特殊 [CLS] 标记的最终隐藏向量表示为,第 i 个输入标记的最终隐藏向量表示为。
对于给定的 token , BERT 输入表示是通过将相应的 token 、 segment (段) 和 position (位置) embedding 相加来构建的。图 2 显示了该结构的可视化。
# 2.3 预训练 BERT
使用两个无监督任务对 BERT 进行预训练。
# (1) 任务 1:掩码语言模型(Masked LM, MLM)
为了训练深度双向表示, BERT 随机屏蔽一定比例的输入 token ,然后预测这些被屏蔽的 token 。这一过程称为 Masked LM ( MLM ),在文献中它通常被称为完形填空任务。
训练数据生成器随机选择 15% 的 token 位置进行预测。如果选择了第 个 token ,那么 80% 的概率使用 [MASK] token ,10% 的概率使用随机 token ,10% 的概率使用未更改的第 个 token 来替换第 个 token 。然后,利用 来预测具有交叉熵损失的原始 token 。
# (2)任务 2:下一个句子预测(Next Sentence Prediction, NSP)
许多重要的下游任务,如问答 ( QA ) 和自然语言推理 ( NLI ),都是基于理解两个句子之间的关系,这是语言建模无法直接捕获的。为了训练一个理解句子关系的模型, BERT 对一下一个句子预测任务进行了预训练,该任务可以从任何单语语料库中轻松生成。具体来说,当为每个预训练示例选择句子 A 和 B时 , 50% 的时间 B 是 A 之后的下一个句子 (标记为 IsNext ), 50% 的时间 B 是语料库中的随机句子 (标记为 NotNext )。如图 1 所示, 用于下一个句子预测。
# 预训练的数据
预训练过程在很大程度上遵循现有的文献语言模型预训练。对于预训练语料库, BERT 使用 BooksCorpus (8 亿单词)和英语维基百科(2,500 万字)。对于维基百科, BERT 只提取文本段落,忽略列表,表格和标题。使用文档级语料库而不是诸如十亿字基准,以便提取长的连续序列。
# 2.3 微调 BERT
在海量的语料上训练完 BERT 之后,便可以将其应用到 NLP 的各个任务中了。 微调 (Fine-Tuning) 的任务包括:基于句子对的分类任务,基于单个句子的分类任务,问答任务,命名实体识别等。
# 三、参考程序
https://github.com/codertimo/BERT-pytorch