# 一、引言
自从 CLIP 横空出世,各种 视觉语言预训练 ( Vision-Language Pre-training, VLP ) 模型逐渐涌现,显著提高了各种视觉语言任务的性能。然而,现有的 VLP 方法主要存在以下两个问题:
-
模型角度:大多数方法都是基于 编码器模型 (
encoder-based model) 或编码器 - 解码器模型 (encoder-decoder models),前者难以完成文本生成任务,后者无法完成图像文本检索任务,这两项任务无法兼顾; -
数据角度:以
CLIP为代表的方法都是从互联网上收集海量图像 - 文本对作为样本进行预训练,这些带噪声的文本作为视觉语言学习的监督信号显然不是最优解;
为此, Salesforce 的研究者们提出了 BLIP (Bootstrapping language - image Pre-training) ,用于统一的视觉语言理解和生成。 BLIP 是一种新的 VLP 框架,比现有方法能够实现更广泛的下游任务。它分别从模型和数据的角度介绍了两个贡献:
-
编码器 - 解码器的多模态混合 (
MED, Multimodal mixture of Encoder-Decoder): 一种有效的多任务预训练和灵活迁移学习的新模型架构。MED可以作为单模编码器、基于图像的文本编码器或基于图像的文本解码器操作。该模型采用图像文本对比学习、图像文本匹配和图像条件化语言建模三个视觉语言目标进行联合预训练。 -
字幕和过滤 (
CapFilt, Captioning and Filtering): 一种新的数据集bootstrap方法,用于从噪声图像 - 文本对中学习。BLIP将预训练的MED调整为两个模块:一个captioner用于生成给定 web 图像的合成字幕,一个filter用于从原始web文本和合成文本中去除嘈杂的字幕。
# 二、相关工作
# 2.1 视觉语言预训练
视觉语言预训练 ( VLP ) 旨在通过对大规模图像 - 文本对模型进行预训练来提高下游视觉和语言任务的性能。由于获取人工注释文本的费用过高,大多数方法使用从网络抓取的图像和替代文本对。尽管使用了简单的基于规则的过滤器,噪声在网络文本中仍然普遍存在。然而,噪声的负面影响在很大程度上被忽略了,被通过扩大数据集获得的性能增益所掩盖。 BLIP 的论文表明,噪声网络文本对于视觉语言学习是次优的,并提出 CapFilt 以更有效的方式利用网络数据集的。
已经有很多尝试将各种视觉和语言任务统一到一个框架中。最大的挑战是设计既能执行基于理解的任务 (如图像文本检索) 又能执行基于生成的任务 (如图像字幕) 的模型架构。两者都不是基于编码器的模型和编码器 - 解码器模型可以在这两种类型的任务中表现出色,而单一的统一编码器 - 解码器也限制了模型的能力。 BLIP 提出的多模态编码器 - 解码器混合模型在广泛的下游任务上提供了更大的灵活性和更好的性能,同时保持了预训练的简单和高效。
# 2.2 知识蒸馏
知识蒸馏( KD, Knowledge Distillation )旨在通过从教师模型中提取知识来提高学生模型的性能。自我蒸馏是 KD 的一个特例,其中教师和学生的规模相等。已经证明只是蒸馏对于图像分类,以及 VLP 是有效的。与大多数现有的 KD 方法只是简单地强制学生具有与教师相同的类预测不同, BLIP 提出的 CapFilt 可以被解释为在 VLP 环境下执行 KD 的一种更有效的方法,其中字幕器通过语义丰富的合成字幕提取其知识,而过滤器通过去除噪声字幕提取其知识。
# 2.3 数据增强
虽然数据增强( DA, Data Augmentation )已被广泛应用于计算机视觉,但用于语言任务的 DA 并不那么直接。近年来,生成语言模型已被用于合成各种 NLP 任务的示例。不同于这些方法只关注低资源的语言任务, BLIP 的方法展示了合成字幕在大规模视觉语言预训练中的优势。
# 三、方法
# 3.1 模型架构
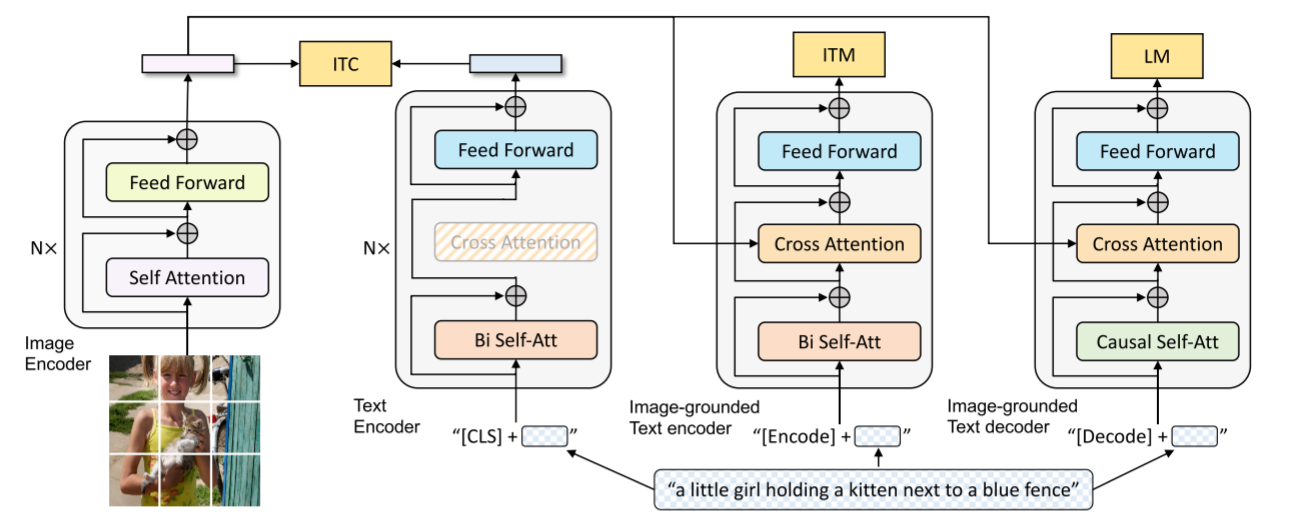
BLIP 采用了编码器 - 解码器的多模态混合结构 ( MED ),包括两个单模态编码器、一个以图像为基础的文本编码器和一个以图像为基础的文本解码器:
-
单模态编码器
lmage Encoder:基于transformer的ViT的架构,将输入图像分割为多个的patch并将它们编码为一系列Image Embedding,并使用 [CLS] token 来表示全局的图像特征。lmage Encoder用来提取图像特征做对比学习,相当于CLIP中的Image Encoder; -
单模态编码器
Text Encoder:基于BERT的架构,将 [CLS] token 加到输入文本的开头以总结句子。Text Encoder用来提取文本特征做对比学习,相当于CLIP中的Text Encoder; -
以图像为基础的编码器
Image-grounded text encoder:对Text Encoder的每一个transformer块,在 自注意力 (self-attention, SA) 层和前馈网络之间添加一个交叉注意 (cross-attention, CA) 层用来注入视觉信息,还将 [Encode] token 加到输入文本的开头以标识特定任务。Image-grounded text encoder用来提取文本特征并将其和图像特征对齐,相当于CLIP中更精细化的Text-Image对齐; -
以图像为基础的解码器
Image-grounded text decoder:将Image-grounded text encoder的self-attention层换成causal self-attention层,还将 [Decode] token 和 [EOS] token 加到输入文本的开头和结尾以标识序列的开始和结束。Image-grounded text decoder用来生成符合图像和文本特征的文本描述,这是CLIP中所没有的;
# 3.2 预训练目标
BLIP 在预训练期间联合优化三个目标,其中两个基于理解的目标和一个基于生成的目标。每个图像 - 文本对仅需要通过计算量较大的视觉 Transformer 的一次正向传递,以及通过文本 Transformer 的三次正向传递,其中不同的功能被激活以计算如下所述的三个损失。
-
图文对比损失 (
Image-Text Contrastive Loss, ITC):ITC用于训练lmage Encoder和Text Encoder,通过对比学习对齐图像和文本的特征空间。具体方法是最大化正样本图像 - 文本对的相似度且最小化负样本图像 - 文本对的相似度。BLIP还使用了ALBEF中的动量编码器来生成特征,并从动量编码器创建软标签作为训练目标,以解释负样本对中的潜在正样本; -
图文匹配损失 (
Image-Text Matching Loss, ITM):ITM用于训练Image-grounded text encoder,通过学习图像 - 文本对的联合表征实现视觉和语言之间的细粒度对齐。具体方法是通过一个二分类任务,预测图像文本对是正样本还是负样本。这里还使用了ALBEF中的hard negative mining技术以更好地捕捉负样本信息;
- 语言建模损失 (
Language Modeling Loss, LM):LM用于训练Image-grounded text decoder,实现生成图像的文本描述任务。具体方法是通过优化交叉熵损失函数,训练模型以自回归的方式最大化文本的概率。在计算损失时,BLIP应用 0.1 的标签平滑。与VLP中广泛使用的MLM损失相比,LM使该模型具有泛化能力,能够将视觉信息转换为连贯的字幕。
# 3.3 CapFilt 机制
COCO 数据集的高质量人工注释图像 - 文本对 数量有限,因此 CLIP 、 BLIP 等 VLP 都是从网络中收集大量图像 - 文本对 作为训练集。但这些网络图像 - 文本对的文本来自图像上下文,难以精准地描述图像内容,存在大量噪声。于是, BLIP 提出了字幕和过滤 ( Captioning and Filtering, CapFilt ) 机制,下图给出了 CapFilt 的说明。
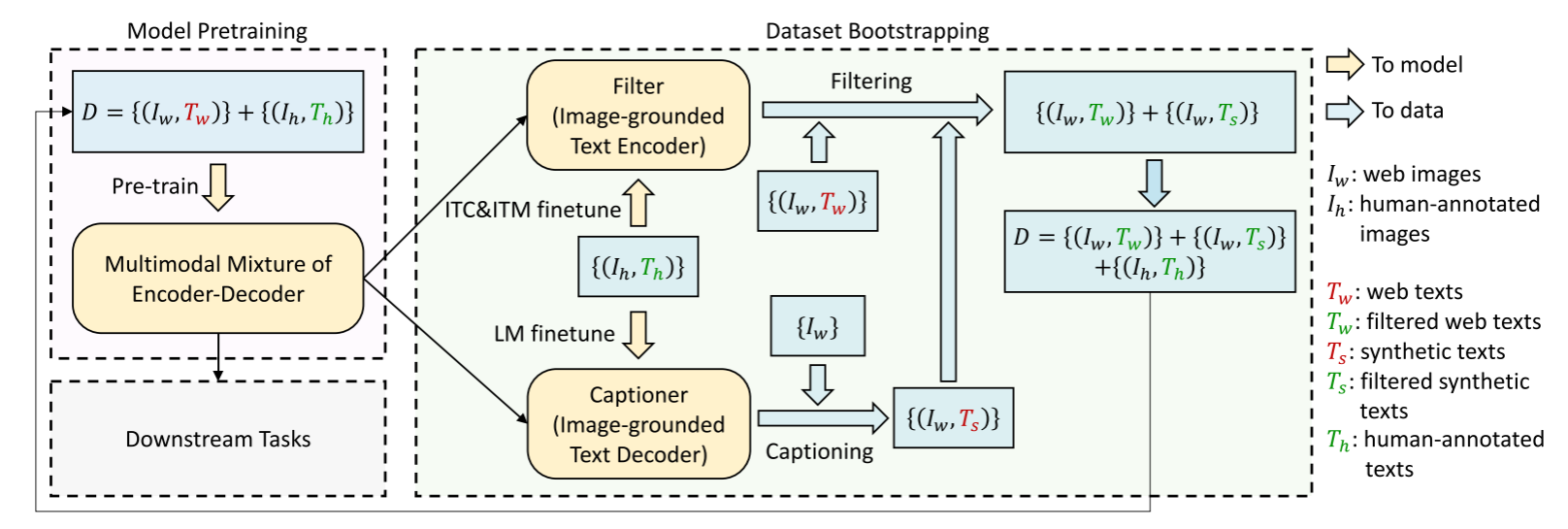
上图给出了 CapFilt 的图示,包含字幕器和过滤器两个模块:
- 字幕器
Captioner:一个视觉文本解码器,基于Image-grounded text decoder,用于生成给定图像的字幕,使用LM损失函数在COCO数据集上进行微调。给定网络图片,Captioner 生成字幕。
- 过滤器
Filter:一个视觉文本编码器,基于Image-grounded text encoder,用于去除文本噪声,使用ITC和ITM损失函数在COCO数据集上进行微调。Filter通过比对文本和图像的匹配情况,删除原始Web文本 和合成文本 中的噪声。
# 3.4 整体思路整理
- 先使用含有噪声的网络数据训练一遍
BLIP; - 再在
COCO数据集上进行微调以训练Captioner和Filter; - 然后使用
Filter从原始网络文本和Captioner合成的文本中删除嘈杂的字幕,得到干净的数据; - 最后再使用干净的数据训练一遍得到高性能的
BLIP。
# 四、参考程序
参考:https://huggingface.co/Salesforce/blip-image-captioning-large
from PIL import Image | |
from transformers import BlipProcessor, BlipForConditionalGeneration | |
processor = BlipProcessor.from_pretrained("E:/python/else/LLM_learn/5_BLIP/model") | |
model = BlipForConditionalGeneration.from_pretrained("E:/python/else/LLM_learn/5_BLIP/model").to("cuda") | |
raw_image = Image.open('1.jpg').convert('RGB') | |
# conditional image captioning | |
text = "a photography of" | |
inputs = processor(raw_image, text, return_tensors="pt").to("cuda") | |
out = model.generate(**inputs) | |
print(processor.decode(out[0], skip_special_tokens=True)) | |
# unconditional image captioning | |
inputs = processor(raw_image, return_tensors="pt").to("cuda") | |
out = model.generate(**inputs) | |
print(processor.decode(out[0], skip_special_tokens=True)) |