# 一、引言
在没有人类监督的情况下学习有效的视觉表征是一个长期存在的问题。大多数主流方法可分为两类:生成式或判别式。生成式方法学习在输入空间中生成或以其他方式建模像素。然而,像素级生成在计算上是昂贵的,并且对于表示学习可能不是必需的。判别方法使用类似于用于监督学习的目标函数来学习表征,但训练网络执行借口任务,其中输入和标签都来自未标记的数据集。许多这样的方法都依赖于启发式来设计借口任务,这可能会限制学习表征的一般性。基于潜在空间中对比学习的判别方法最近显示出很大的前景,取得了最先进的结果。
其中 SimCLR 为视觉表征的对比学习引入了一个简单的框架。 SimCLR 不仅优于以前的工作,而且更简单,不需要专门的架构,也不是记忆库。通过系统地研究 SimCLR 框架,表明了以下促成了良好对比表征学习的主要原因:
- 多个数据增强操作的组合对于定义产生有效表示的对比预测任务至关重要。此外,与有监督学习相比,无监督对比学习受益于更强的数据增强。
- 在表示和对比损失之间引入可学习的非线性变换,大大提高了学习到的表示的质量。
- 具有对比交叉熵损失的表征学习得益于归一化嵌入和适当调整的温度参数。
- 对比学习与监督学习相比,得益于更大的批处理规模和更长的训练时间。与监督式学习一样,对比式学习也受益于更深入、更广泛的网络。
# 二、对比学习框架
受最近的对比学习算法的启发, SimCLR 通过潜在空间中的对比损失来最大化相同数据示例的不同增强视图之间的一致性来学习表示。如下图所示,该框架由以下四个主要组件组成:
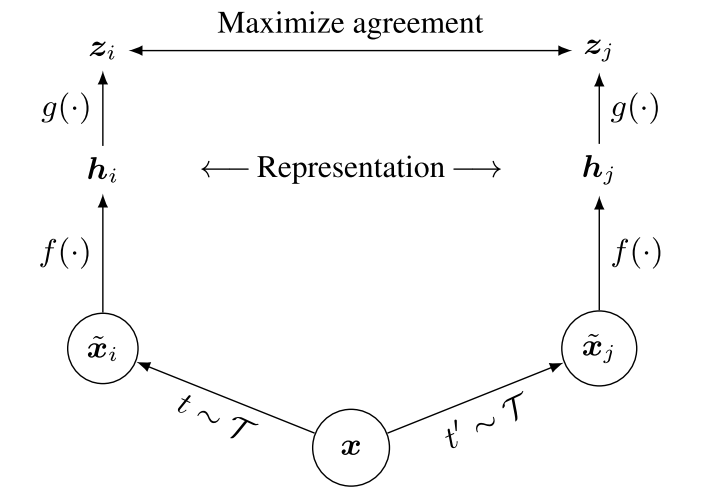
- 一种随机数据增强模块,它将任意给定的数据示例 通过数据增强随机转换为同一示例的两个相关视图,表示为 和,我们将其视为正样本对。在
SimCLR中,依次应用三种简单的增强:随机裁剪,然后将大小调整回原始大小,随机颜色失真和随机高斯模糊。随机裁剪和颜色失真的结合对于获得良好的性能至关重要。 - 一种神经网络基础编码器,从增强的数据示例中提取表示向量。
SimCLR允许在没有任何限制的情况下选择各种网络架构。为了简单起见,采用常用的 ResNet 得到,其中 是平均池化层后的输出。 - 一个小的神经网络投影头,它表示映射到应用对比损失的空间。
SimCLR使用具有一个隐藏层的MLP得到,其中 是一个ReLU非线性。将对比损失定义在 上而不是 上是有益的。 - 为对比预测任务定义的对比损失函数。给定一个集合,其中包含一对正的例子 和,对比预测任务旨在识别给定,在 中的。
通过随机抽取一个由 n 个样本组成的小批量样本,对该小批量样本进行数据增强,得到 2N 个数据点。对于每一个增强后的数据,都对应一个正样本,将增强后数据中的其他 2 (N−1) 个增强示例视为负示例。设 表示归一化 与 之间的点积 (即余弦相似度)。则一对正样本 的损失函数定义为
其中 是当 时取值为 1 的指标函数, 表示温度参数。为了方便起见,称其为 NT-Xent (the normalized temperature-scaled cross entropy loss,归一化温度标度交叉熵损失)。
如下的流程图总结了 SimCLR 的算法流程:

# 三、对比表征学习的数据增强
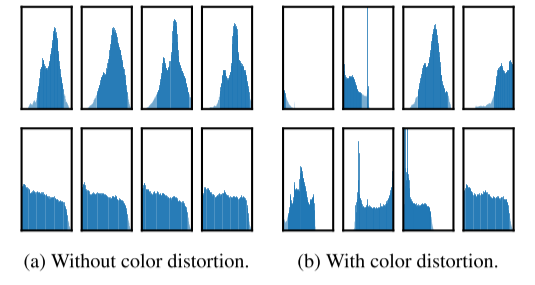
为了系统地研究数据扩充的影响, SimCLR 这里考虑几个常见的扩充。一种类型的增强涉及数据的空间 / 几何变换,例如裁剪和调整大小 (水平翻转),旋转和切出。另一种类型的增强涉及外观转换,如颜色失真 (包括颜色下降,亮度,对比度,饱和度,色调),高斯模糊和索贝尔滤波。下图显示了 SimCLR 中学习的增强。

下图显示了单独和组合转换下的线性评估结果。可以观察到,即使模型几乎可以完美地识别对比任务中的正对,也没有一个单一的变换足以学习到良好的表示。在组合增强时,对比预测任务变得更加困难,但表示质量显著提高。
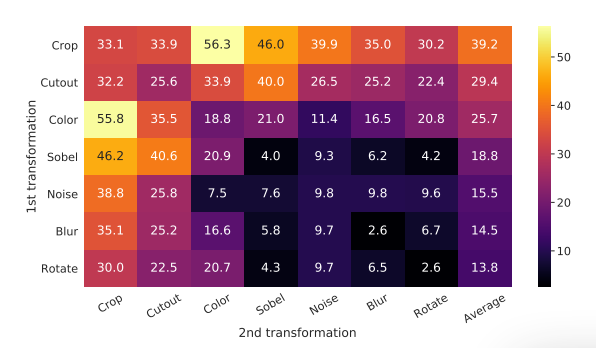
增强的一个组成突出:随机裁剪和随机颜色失真。可以推测,当只使用随机裁剪作为数据增强时,一个严重的问题是来自图像的大多数补丁共享相似的颜色分布。下图显示,颜色直方图本身就足以区分图像。神经网络可以利用这一捷径来解决预测任务。因此,为了学习可推广的特征,将裁剪与颜色失真组合是至关重要的。
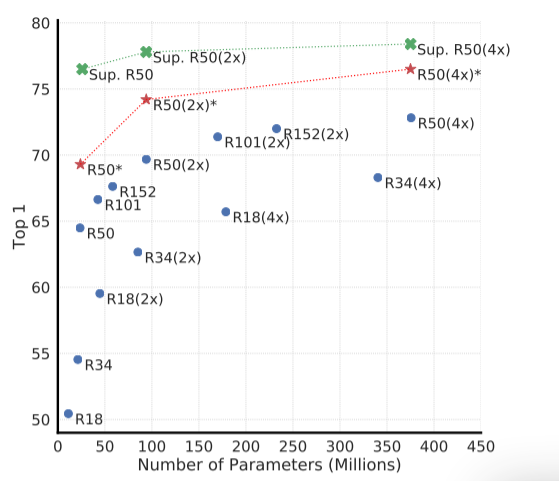
# 四、编码器和投影头的架构
下图显示,增加深度和宽度都会提高性能,这也许并不令人惊讶。虽然类似的发现适用于监督学习,我们发现监督模型和在无监督模型上训练的线性分类器之间的差距随着模型大小的增加而缩小,这表明无监督学习比监督学习更受益于更大的模型。
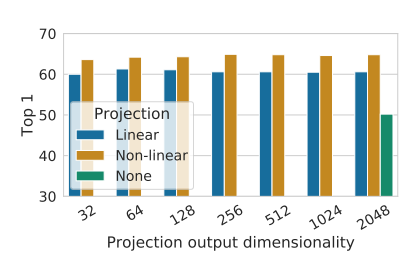
然后, SimCLR 研究包括投影头的重要性,即。下图示出了使用头部的三种不同架构的线性评估结果:(1)无投影;(2)线性投影;(3)默认的非线性投影与一个额外的隐藏层(ReLU 激活)。可以观察到非线性投影比线性投影好(+3%),并且比没有投影好得多(>10%)。当使用投影头时,无论输出尺寸如何,都观察到类似的结果。