# 一、引言
虽然 Transformer 架构已成为 NLP 任务的首选模型,但它在 CV 中的应用仍然有限。在视觉上,注意力要么与卷积网络结合使用,要么用于替换卷积网络的某些组件,同时保持其整体结构。而这种对 CNNs 的依赖是不必要的,直接应用于图像块序列 ( sequences of image patches ) 的纯 Transformer 可以很好地执行图像分类任务。当对大量数据进行预训练并迁移到多个中小型图像识别基准时 ( ImageNet 、 CIFAR-100 、 VTAB 等),与 SOTA 的 CNN 相比, Vision Transformer (ViT) 可获得更优异的结果,同时仅需更少的训练资源。
# 二、方法
在模型设计中, ViT 尽可能地遵循原始 Transformer 。 这种有意简单设置的优势在于,可扩展的 NLP Transformer 架构及其高效实现几乎可以开箱即用。
# 2.1 图像块嵌入 (Patch Embeddings)
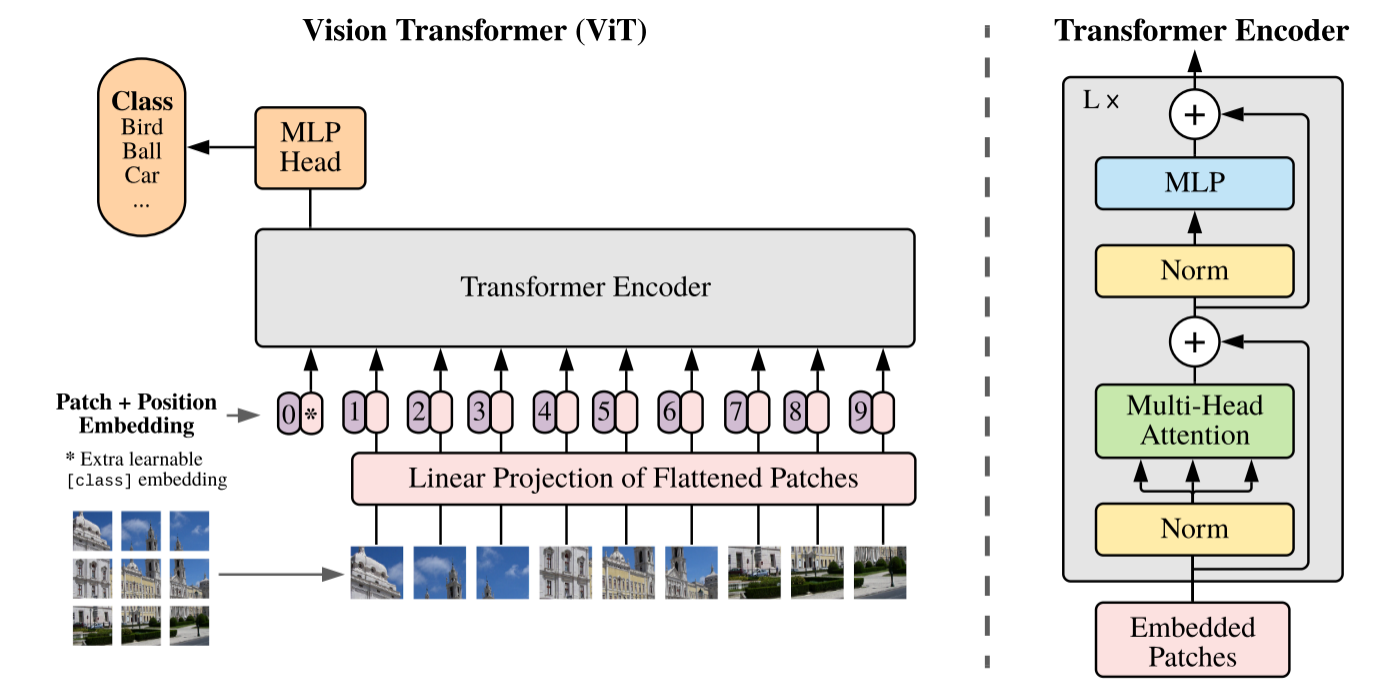
模型概述如图 1 所示。标准 Transformer 使用一维标记嵌入序列 ( Sequence of token embeddings ) 作为输入。为了处理 2D 图像,将图像 reshape 为一个展平的 2D patches 序列
其中 (H,W) 是原始图像的分辨率,C 是通道的数目,(P,P)是每个图像片的分辨率,并且 是得到图像 patch 的数,也是 Transformer 的有效输入序列长度。 Transformer 在其所有层中使用恒定的潜在向量大小 D ,因此 ViT 将 pathches 展平,并使用 ** 可训练的线性投影 (FC 层)** 将 映射到 D 维,同时保持图像 patches 数 N 不变。该投影的输出被称为 patch embeddings 。
上述投影输出即为图像块嵌入 (Patch Embeddings),本质就是对每一个展平后的 patch vector 做一个线性变换 / 全连接层 ,由 降维至 维,得到。类似于 NLP 中的词嵌入(Word Embeddings)。
图像块嵌入的参考程序为:
class PatchEmbed(nn.Module): | |
""" Image to Patch Embedding """ | |
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768): | |
super().__init__() | |
# (H, W) | |
img_size = to_2tuple(img_size) | |
# (P, P) | |
patch_size = to_2tuple(patch_size) | |
# N = (H // P) * (W // P) | |
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0]) | |
self.img_size = img_size | |
self.patch_size = patch_size | |
self.num_patches = num_patches | |
# 可训练的线性投影 - 获取输入嵌入 | |
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size) | |
def forward(self, x): | |
B, C, H, W = x.shape | |
# (B, C, H, W) -> (B, D, (H//P), (W//P)) -> (B, D, N) -> (B, N, D) | |
# D=embed_dim=768, N=num_patches=(H//P)*(W//P) | |
# torch.flatten (input, start_dim=0, end_dim=-1) # 形参:展平的起始维度和结束维度 | |
# 可见 Patch Embedding 操作 1 行代码 3 步到位 | |
x = self.proj(x).flatten(2).transpose(1, 2) | |
return x |
# 2.2 可学习的嵌入(Learnable Embedding)
类似于 BERT 的 [class] token, ViT 为图像 patch 嵌入序列预设一个可学习的嵌入,其在 Transformer 编码器输出的状态 / 特征 用作图像表示。在预训练和微调期间,将分类头附加到 之后,从而用于图像分类。分类头在预训练时由具有一个隐藏层的 MLP 实现,在微调时由单个线性层实现。
更明确地,假设将图像分为 N 个图像块,输入到 Transformer 编码器中就有 N 个向量,但是这些向量都不适合用来作为分类预测。一个合理的做法是手动添加一个可学习的嵌入向量作为用于分类的类别向量同时与其他图像块嵌入向量一起输入到 Transformer 编码器中,最后取追加的首个可学习的嵌入向量作为类别预测结果。所以,追加的首个类别向量可理解为其他 N 个图像块寻找的类别信息。从而,最终输入 Transformer 的嵌入向量总长度为 N+1。可学习嵌入 在训练时随机初始化,然后通过训练得到,其具体实现为:
### 随机初始化 | |
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim)) # shape = (1, 1, D) | |
# 按通道拼接 获取 N+1 维 Embeddings | |
x = torch.cat((cls_tokens, x), dim=1) # shape = (B, N+1, D) |
# 2.3 位置嵌入 (Position Embeddings)
位置嵌入 也被加入图像块嵌入,以保留输入图像块之间的空间位置信息。若不给模型提供图像块的位置信息,那么模型就需要通过图像块的语义来学习拼图,这就额外增加了学习成本。ViT 论文中对比了几种不同的位置编码方案:
- 位置嵌入
- 1-D 位置嵌入 (1D-PE):考虑把 2-D 图像块视为 1-D 序列
- 2-D 位置嵌入 (2D-PE):考虑图像块的 2-D 位置 (x, y)
- 相对位置嵌入 (RPE):考虑图像块的相对位置
最后发现如果 不提供位置编码效果会差,但其它各种类型的编码效果效果都接近,这主要是因为 ViT 的输入是相对较大的图像块而非像素,所以学习位置信息相对容易很多。
Transformer 原文中默认采用 固定位置编码,ViT 则采用 标准可学习 / 训练的 1-D 位置编码嵌入,因为尚未观察到使用更高级的 2-D-aware 位置嵌入 (附录 D.4) 能够带来显著的性能提升 (当然,后续的很多 ViT 变体也使用了 2-D 位置嵌入)。在输入 Transformer 编码器之前直接 将图像块嵌入和位置嵌入按元素相加:
# 多 +1 是为了加入上述的 class token | |
# embed_dim 即 patch embed_dim | |
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim)) | |
# patch emded + pos_embed :图像块嵌入 + 位置嵌入 | |
x = x + self.pos_embed |