# 一、MAE 概述
深度学习在计算机视觉领域取得了显著进展,但随着模型规模的增长,对数据的需求也在增加。在自然语言处理( NLP )领域,通过自监督预训练的方法(如 BERT 和 GPT )成功解决了数据需求问题,这些方法通过预测数据中被 masked 的部分来训练模型。然而,在计算机视觉领域,尽管存在相关研究,自监督学习方法的发展仍然滞后于 NLP 。
这篇论文使用掩码自编码器 ( masked autoencoders (MAE) ) 进行自监督学习。这种类型自监督学习的另一个著名的例子就是 BERT 。
对于 BERT 模型而言,一个 sentence 中间盖住一些 tokens ,让模型去预测,令得到的预测结果与真实的 tokens 之间的误差作为损失。它告诉了我们直接 reconstruct sentence 也可以做到很 work 。
对于 MAE 模型而言,一个 image 中间盖住一些 patches ,让模型去预测,令得到的预测结果与真实的 image patches 之间的误差作为损失。它告诉了我们直接 reconstruct image 原图也可以做到很 work 。
为什么 BERT (2018) 提出这么久以后,直到 BEIT (2021.6) 和 MAE (2021.11) 之前,一直在 CV 领域都没有一个很类似的 CV BERT 出现?这里 Kaiming 提出了 3 条看法:
- CV 和 NLP 主流架构不同:直到
ViT (2020.12)出现之前,CV的主流架构一直是以卷积神经网络为主,NLP的主流架构一直是以Transformer为主。卷积核作用在一个个的grid上面,直观来讲没法产生像Transformer一样的token的概念,也就是说如果我们只使用卷积网络,那么image token概念的建立就不那么直观。所以,像Transformer那样在token的基础上进行自监督学习就不太适用,这是第一个难点。 - 语言和图片 (视频) 的信息密度不同:语言是人类造就的信号,它
highly semantic,information-dense。而图片 (视频) 是自然产生的信号,它heavy spatial redundancy。即挡住图片的一部分patches,可以很容易地通过看它周围的patches而想象出它的样子来。所以,语言和图像,一个信息密度高,一个信息密度低,这是第二个难点。解决的办法是什么呢?作者提出了一个简单的策略:即挡住图片的 patches 的比例高一些。比如之前你挡住一张图片的30%的patches,能够轻松通过周围的patches预测出来;那现在如果挡住图片的 90% 的 patches,还能够轻松通过周围的patches预测出来吗? - AutoEncoder 里面的 Decoder 部分在 CV 和 NLP 中充当的角色不同:在
CV领域,Decoder的作用是重建image pixels,所以Decoder的输出语义级别很低。在NLP领域,Decoder的作用是重建sentence words,所以Decoder的输出语义级别很丰富。
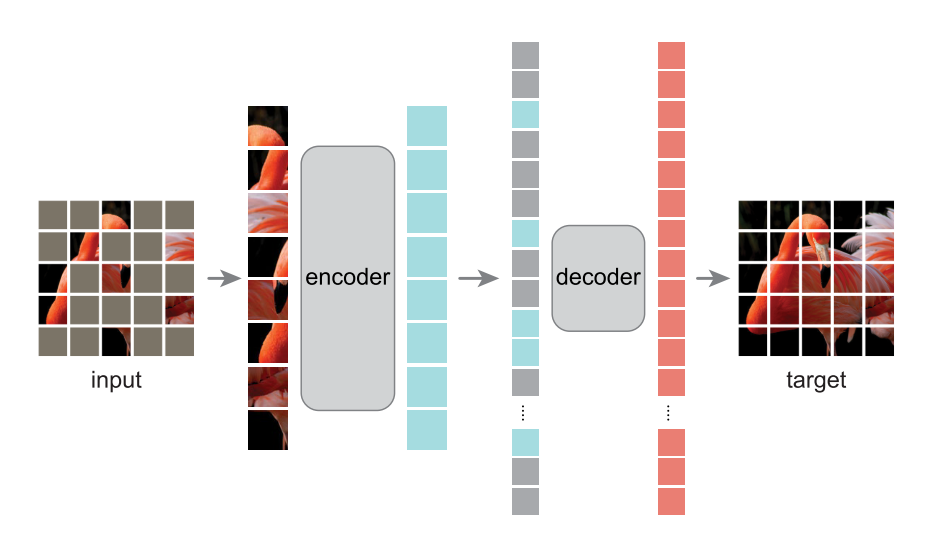
基于以上分析,作者提出了 MAE 方法,其架构如上图所示。 MAE 的方法很简单: Mask 掉输入图像的随机的 patches 并重建它们。它基于两个核心理念:
- 作者开发了一个非对称
Encoder-Decoder架构,其中一个Encoder只对可见的patch子集进行操作 (即没有被 mask 掉的 token),另一个简单轻量化的Decoder可以从潜在表征和被 masked 掉的 token 重建原始图像。 - 研究人员进一步发现,Mask 掉大部分输入图像 (例如
75%) 会产生重要且有意义的自监督任务。
结合这两种设计,就能高效地训练大型模型:提升训练速度至 3 倍或更多,并提高准确性。
MAE 方法严格来讲属于一种去噪自编码器 ( Denoising Auto-Encoders (DAE) ), DAE 是一类自动编码器,它破坏输入信号,并学会重构原始的、未被破坏的信号。 MAE 的 Encoder 和 Decoder 结构不同,是非对称式的。 Encoder 将输入编码为 latent representation ,而 Decoder 将从 latent representation 重建原始信号。
MAE 和 ViT 的做法一致,将图像划分成规则的,不重叠的 patches 。然后按照均匀分布不重复地选择一些 patches 并且 mask 掉剩余的 patches 。作者采用的 mask ratio 足够高,因此大大减小了 patches 的冗余信息,使得在这种情况下重建 images 不那么容易。
# 二、MAE 方法
# 2.1 Mask
根据 ViT , MAE 将图像划分为规则的不重叠的 patch 。然后对 patch 的子集进行采样,并 mask (即删除) 剩余的 patch 。 MAE 的采样策略很简单:对随机 patch 进行采样,遵循均匀分布。简单地称之为 “随机抽样”。
具有高 mask ratio`(即去除斑块的比例) 的随机采样在很大程度上消除了冗余,从而创建了一个不能通过从可见的邻近斑块外推轻松解决的任务。均匀分布防止了潜在的中心偏差 (即在图像中心附近有更多的掩蔽斑块)。最后,高度稀疏的输入为设计高效的编码器创造了机会。
# 2.2 MAE encoder
MAE 的编码器是 ViT ,但只应用于可见的,未 mask 的 patches 。就像在标准 ViT 中一样, MAE 的编码器通过添加 positional embedding 的线性投影获得每个 patch 的 embedding ,然后通过一系列 transformer 块处理结果集。 MAE 的编码器只在完整 patches 的一小部分 (例如,25%) 上运行。 masked patches 被移除;且不使用掩码令牌。这允许 MAE 只用一小部分的计算和内存训练非常大的编码器。完整的 patches 由一个轻量级解码器处理。
# 2.3 MAE decoder
MAE 解码器的输入是一个完整的 tokens ,由 (i) 编码的 visible patches 和 (ii) masked tokens 组成。每个 masked tokens 是一个共享的、可学习的向量,表示待预测的 missing patch 。为这个完整 tokens 中的所有 token 添加 position embedding ;解码器有另一系列的 transformer 块。
MAE 解码器仅在预训练期间用于执行图像重建任务 (仅编码器用于生成用于识别的图像表示)。因此,解码器架构可以以一种独立于编码器设计的方式灵活设计。 MAE 用非常小的解码器做实验,比编码器更窄更浅。例如,与编码器相比,我们的默认解码器每个令牌的计算量 < 10%。通过这种不对称设计,整个标记集只由轻量级解码器处理,这大大减少了预训练时间。
# 2.4 Reconstruction target
MAE 通过预测每个 masked patch 的像素值来重构输入。解码器输出中的每个元素都是表示一个 patch 的像素值向量。解码器的最后一层是线性投影,其输出通道的数量等于 patch 中的像素值的数量。 MAE 的损失函数在像素空间中计算重建图像和原始图像之间的均方误差( MSE )。 MAE 只计算 masked patches 上的损失,类似于 BERT 。
MAE 还研究了一种变体,其重建目标是每个 masked patch 的归一化像素值。具体地说, MAE 计算一个 patch 中所有像素的平均值和标准差,并使用它们来归一化该 patch 。在 MAE 的实验中,使用归一化像素作为重建目标改善了表示质量。
# 2.5 Simple implementation
MAE 的预训练可以有效地实现,并且重要的是,不需要任何专门的稀疏操作。
- 首先,我们为每个输入
patch生成一个token(通过添加position embedding的线性投影)。 - 接下来,我们随机打乱
token列表,并根据mask ratio删除列表的最后一部分。此过程为编码器生成一个小的token子集。 - 在编码之后,我们将
mask token的列表添加至编码的token列表,并还原此完整的列表(反转随机打乱操作),以将所有token与其目的对齐。 - 解码器应用于该完整列表(添加了位置嵌入)。
如上所述,不需要稀疏操作。由于打乱和还原操作是快速的,因此这种简单的实现引入了可忽略的开销。