参考链接:https://blog.csdn.net/qq_27590277/article/details/142466419
等待学习的技术:Common Crawl、Fasttext、MinHash+LSH、MuggleMath、DotaMath、拒绝微调(RFT)、GRPO、13-gram matching、ChatLearn5
# 一、引言
从 Qwen2.5-Math 的技术报告副标题:“Toward Mathematical Expert Model via Self-Improvement”,可以看出,Self-Improvement 是一个贯穿整个 Qwen2.5-Math 训练流程的重要方法。具体来说,在 Qwen2.5-Math 的训练中,从三个方面进行 Self-Improvement。
-
Pre-training: 用 Qwen2-Math-Instruct 来合成扩充预训练数据;
-
Post-training: SFT 模型和奖励模型之间的交互迭代
-
Inference:奖励模型用于指导采样
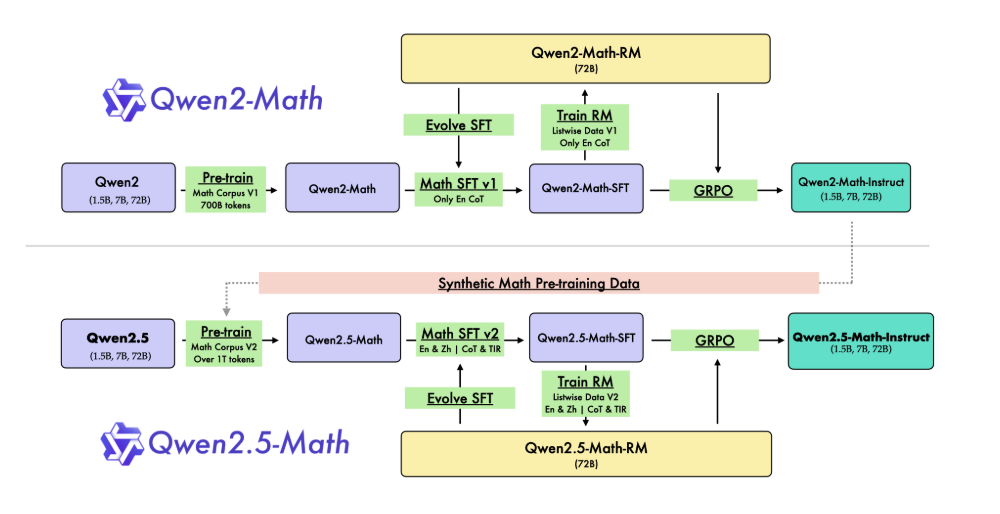
整体开发 Qwen2-Math 和 Qwen2.5-Math 的流程如下:
-
首先,Qwen2-Math base 模型在一个名为 Qwen Math Corpus v1 的高质量数学预训练数据集上进行训练,该数据集包含大约 7000 亿个 token。
-
其次,训练了一个特定于数学的奖励模型 Qwen2-Math-RM,该模型来源于 Qwen2-Math-72B,以创建 Qwen2-Math-Instruct 模型。该奖励模型用于通过拒绝抽样构建监督微调 (SFT) 数据。此外,奖励模型在强化学习阶段起着关键作用,我们在 SFT 之后采用了群体相对策略优化 (GRPO) 。
-
第三,利用 Qwen2-Math-72B-Instruct 模型,合成了额外的高质量数学预训练数据,为 Qwen Math Corpus v2 提供了基础。这个更新的语料库包含超过 1 万亿个令牌,并用于预训练 Qwen2.5-Math 模型。
-
最后,与 Qwen2-Math-Instruct 模型的过程类似,构建了 Qwen2.5-Math-RM 和 Qwen2.5-Math-Instruct 模型。这个阶段的一个重要区别是,在训练 Qwen2.5-Math-Instruct 模型时,包含了英语和汉语的思维链 (CoT) 推理数据,以及工具集成推理 (TIR) 数据,而不是像 Qwen2-Math-Instruct 模型那样只使用英语的思维链 (CoT) 数据。
# 二、Qwen2.5-Math 预训练
# 2.1 Qwen2-Math 预训练流程
在数学预训练中,主要关注的是构建一个富含数学内容的高质量数据集。该数据集包含各种各样的来源,包括与数学相关的网络文本、代码片段、百科全书、考试问题和 Qwen2 生成的合成数学数据。组装这个预训练数据集的过程包括几个关键步骤:数据召回、重复数据删除、过滤、数据合成的和数据混合的优化。最终整理的数据集构成了预训练的基础,被称为 Qwen Math Corpus v1。使用 Qwen2-1.5B/7B/72B 初始化的 Qwen2-Math 基础模型,使用 Qwen2-1.5B/7B/72B 进行连续预训练。
# 2.2 v1 数据集的扩充
一般语言模型在数学推理中的次优性能源于预训练过程中数学数据的不足。Qwen2-Math 的策略包括从 web 来源 (如 Common Crawl) 中召回数学数据,以增加数据量。具体而言,使用高质量的数学种子数据和一般文本数据训练 FastText 分类器。我们利用迭代训练与更多的数学数据,每个 epoch 不断提高分类器的性能。随后,重复数据删除技术,包括 MinHash,被用来过滤掉类似的数学文档。
# 2.3 v1 数据质量的提高
在收集大量数学数据后,重点转向提高其质量。利用 Qwen2-0.5B-Instruct 模型,辅以 prompt engineering,来评估数据的质量。根据语言模型,获得更高分数的数据表明质量更高,将优先包含在最终数据集中。除了过滤掉低质量的数据之外,以已有的参考数据为基础,采用 Qwen2-72B-Instruct 模型来合成大量的数学预训练语料库,包括:(1) 从这些参考数据中提取已有的数学问答数据,(2) 直接生成新的数学问答对。
# 2.4 Qwen2.5-Math 预训练流程
在 Qwen2-Math 基础模型训练之后,通过三个主要途径将其升级为 Qwen2.5-Math 模型:
-
(1) 利用 Qwen2-Math-72B-Instruct 模型,通过第 3 节描述的步骤进行进一步的后训练,合成额外的高质量数学预训练数据。
-
(2) 收集了更多高质量的数学数据,特别是中文数据,这些数据来自多个召回周期的网络文档、书籍和代码库。通过这些努力,获得了用于对 Qwen2.5-Math-1.5B/7B/72B 进行预训练的数学语料库 Qwen Math Corpus v2。与 Qwen Math Corpus v1 相比,Qwen Math Corpus v2 的总令牌计数从 700B 上升到 1T 以上。
-
(3) 利用 Qwen2.5 系列基本模型进行参数初始化,因为它们在语言理解、代码生成和文本推理方面表现出增强的能力。
# 3 Qwen2.5-Math 后训练
在完成广泛的数学预训练后,需要继续进行后训练,以进一步增强 Qwen-Math 的数学逻辑推理能力,特别是专注于思维链 (CoT) 和工具集成推理 (TIR)。其中包含两个关键挑战:
-
(1) 如何自动生成大量高质量和可靠的 CoT 和 TIR 数据
-
(2) 如何有效地利用这些注释进行 SFT 和 RL
# 3.1 监督微调(SFT)
Qwen2.5-Math 构建了思维链 (CoT) 和工具集成推理 (TIR) 的专用数据集,并将这些数据集结合起来共同对模型进行监督微调。
# 3.1.1 思维链(CoT)数据合成
# (1)输入构造
思维链数据集包含了 58 万个英文和 50 万个中文数学问题的广泛集合,包括标注项和合成项。标注问题源自一些知名来源,例如 GSM8K、MATH 和 NuminaMath。同时增加了 K-12 问题集合的中文数学问题。合成问题是通过 MuggleMath 方法从标注问题演变而来的。为了在不同难度水平的问题复杂性上保持均衡分布,我们有效地利用了难度评分模型对问题集进行分类。
# (2)输出构造
采用了一种迭代方法,利用拒绝采样,并结合奖励模型和标注答案,逐步提高响应的质量。在每次迭代中,当前最佳模型被用于为给定问题生成多个推理路径,从而扩展候选解决方案池。
-
对于有标注答案的问题,从候选池中选择最终答案正确的前 k 个推理路径。
-
对于缺乏明确答案的合成问题,实施加权多数投票机制,以推导出最合理的正确推理路径。从中选择获得最高奖励分数的前 k 个路径。
# 3.1.2 工具集成推理(TIR)数据合成
虽然 CoT 提示在提高大型语言模型的推理技能方面起着至关重要的作用,但它在实现计算准确性和处理复杂的数学或算法问题方面面临挑战。例如求二次方程的根或计算矩阵的特征值。为了克服这些限制并提高模型在精确计算、符号操作和算法推理方面的熟练程度,Qwen2.5-Math 开发了一个包含工具集成推理格式的数据集。这种格式的数据使模型能够在推理任务中利用 Python 解释器作为辅助资源。
# (1)输入构造
工具集成推理数据集由 19 万个标注问题和 20.5 万个合成问题组成。标注问题来源于一些知名基准的训练集,包括 GSM8K、MATH、CollegeMath 和 NuminaMath。合成问题是通过采用 MuggleMath 和 DotaMath 中的技术生成的。此外,选择了 75 万个标注问题,使用 Qwen2-72B 模型翻译成中文,以增强模型在中文中的推理能力。
# (2)输出构造
对于标注问题,采用在线拒绝微调(RFT)方法迭代生成工具集成推理路径,使其最终答案与参考答案一致。在每次 RFT 迭代中,使用当前最佳模型进行多次核采样,并在不同温度下增加样本数量。每次迭代后,为了增强数据多样性,我们对响应进行去重处理,得到的清理数据集将用于微调模型以进行下一次迭代。
对于合成问题,采用从在线 RFT 过程中得到的最佳模型生成推理样本。我们使用多数投票法选择最可能正确的推理路径,这些路径随后被纳入整体数据集。
# 3.2 奖励模型训练
为了在选择监督微调数据和随后的强化学习训练阶段提供超出最终答案的监督信号,为 Qwen2-Math 和 Qwen2.5-Math 开发了一个数学奖励模型,分别称为 Qwen2-Math-RM 和 Qwen2.5-Math-RM。这些奖励模型专门设计用于在整个训练过程中指导模型,通过提供更细致的推理质量和中间步骤的反馈,最终促进更稳健的模型改进。
# 3.2.1 数据合成
在 Qwen2-Math-RM 的开发过程中,使用了 206K 的英文数学问题,每个问题都搭配了从 Qwen2-Math 中抽取的 6 个答案。对于 Qwen2.5-Math-RM,进一步增强了其对中文和 TIR 模式的支持,使用了一个更加多样化的数据集对其进行训练,该数据集包含 361K 的英文数学问题和 257K 的中文数学问题,每个问题都附有从 Qwen2.5-Math 中抽取的 6 个答案。这一扩展确保了 Qwen2.5-Math-RM 能够充分胜任在更广泛的问题类型和语言范围内提供监督反馈的任务。
为了在答案之间建立偏好信号,检查了每个答案的正确性。正确答案的回答被标记为积极的,而错误答案的回答被标记为消极的,从而自然地在答案之间创建了一个排名关系。然后,过滤掉所有答案要么完全正确,要么完全错误的情况。为了避免只保留过于简单的数据的潜在缺点,使用来自各种中间版本和不同大小模型的响应来丰富数据集。该策略确保了输入数据难度的更均衡分布,并保持了正响应与负响应的均匀比例。
# 3.2.2 训练策略
从监督微调模型初始化奖励模型。在架构方面,将最初用于下一个 token 预测的语言建模头替换为由两个线性层组成的标量值头。奖励模型训练数据集中的每个输入都与 6 个输出配对。如果有 k 个正样本,则其余 6 - k 个为负样本。奖励模型的损失函数可以表示为:
其中, 表示奖励模型的输出,其中 表示问题输入, 表示相应的输出。该损失函数没有将它们分解成多个单独的对并以成对的方式计算损失,而是采用列表方法直接计算有效对上的排名损失。该方法提高了培训的效率和效果。
# 3.3 增强学习
# 3.3.1 输入选择
用于强化学习训练的输入从奖励模型的训练集中选择。利用不同规模的监督微调模型为每个查询重新采样 8 个响应,并通过与标准答案进行比较,将每个响应分类为正确或不正确。保留 8 个响应中有 2 到 5 个正确答案的查询。少于 2 个正确答案的查询会被排除,因为这表明当前的数学模型缺乏从中学习的基本能力。同样,超过 5 个正确响应的查询也会被排除,因为模型在这些情况下已经表现出能力,无需进一步训练。最终,保留了 66K 个查询用于训练。
# 3.3.2 分组相对策略优化(GRPO)
GRPO 是一种专门为大型语言模型设计的强化学习方法,避免了像 PPO 那样需要额外的值函数近似。GRPO 使用一组抽样输出的平均奖励作为基准来计算每个输出的优势。GRPO 的目标定义为:
# 3.3.3 奖励构造
将基于规则的验证者和奖励模型的奖励结合起来,形成整体的奖励信号。基于规则的验证器从每个响应中提取潜在答案,并将其与标准答案进行比较。
将奖励模型的输出记为,基于规则的验证器的稀疏奖励记为,则总体奖励计算如下:
这种形成机制确保正确的反应始终比错误的反应获得更高的总体奖励。在每个正确和不正确的组中,根据奖励模型的分数对回答进行排名。特别是在复杂问题中。
# 3.3.4 实现
实验是基于开源 RLHF 框架 ChatLearn5 实现的。所有不同参数大小的策略模型都使用相同的奖励模型进行训练。为每个查询采样 32 个响应。所有模型都使用 512 全局批大小进行训练。7B 和 72B 的学习率分别为 和。所有训练的 KL 系数为。屏蔽了 Python 执行器在工具集成推理的强化学习中提供的所有输出令牌。
# 4、去污
去污是确保模型性能评估无偏的关键。Qwen2.5-math 使用 13-gram matching 排除了可能受污染的训练样本。为了提高匹配过程的准确性,执行文本规范化,删除不相关的标点和符号。为了进一步减少假阴性,特别是对于常见的数学表达式,引入了一个额外的标准:
- 最长公共子序列的比率必须超过 0.6,才能认为样本被污染。对于预训练数据,针对 GSM8K 和 MATH 等数据集过滤可能受污染的样本。
在处理后训练数据时,包括 SFT 数据、RM 训练数据和 RL 查询集,在所有报告的评估数据集中排除任何潜在的污染问题或解决方案。这些评估数据集包括 GSM8K 、MATH 、Minerva MATH 、Gaokao 2023 En、Olympiad Bench、College Math、MMLU STEM 、Gaokao、CMATH、CN Middle School 24,AIME 24 和 AMC 23。在对污染样本的分析过程中,发现一些现有的训练数据集 (例如,MATH 训练数据集) 包含了与测试数据集中发现的问题具有高度相似的概念或结构的显著比例。虽然这些变化不是完全重复的,但它们可能会损害评估的完整性。因此,需要从训练语料库中排除这样的样本。