参考连接:https://zerolovesea.github.io/2024/05/12 / 分布式训练:了解 Deepspeed 中的 ZeRO1-2-3/
# 一、Deepspeed 介绍
DeepSpeed 是微软推出的大规模模型分布式训练的工具,分布式训练场景目前主要分成三个策略:
- 数据并行
- 模型并行
- 流水线并行
在数据并行的策略下,每个模型都需要跑一个完整的模型,这时就需要考虑训练模型占用的参数量。ZeRO 就是为了解决这个问题而诞生的。
ZeRO 的全称是 Zero Redundancy Optimizer,意为去除冗余的优化器。在分布式训练中,主要占用的参数主要分为了三个部分:模型参数(Parameters),优化器状态(Optimizer States),梯度 (Gradients),他们三个简称为 OPG 。其中优化器状态会占据大约 2 倍参数量的显存空间,这取决于选择的优化器,也是整个训练中占据最大空间的部分。为了解决这个问题,ZeRO 提供了另一种思路:使用切片来达到时间换空间的效果。
# 二、ZeRO 的三个级别
ZeRO 被分为了四个级别:
- ZeRO-0:不进行任何形式的状态分片,只把 DeepSpeed 当成数据并行分布式(DDP, Distributed Data Parallel)来用。
- ZeRO-1:对优化器状态进行拆分。显存消耗减少 4 倍,通信量与数据并行相同。
- ZeRO-2:在 ZeRO-1 的基础上,对梯度进行拆分。显存消耗减少 8 倍,通信量与数据并行相同。
- ZeRO-3:在 ZeRO-2 的基础上,对模型参数进行拆分。模型占用的显存被平均分配到每个 GPU 中,显存消耗量与数据并行的并行度成线性反比关系,但通信量会有些许增加。
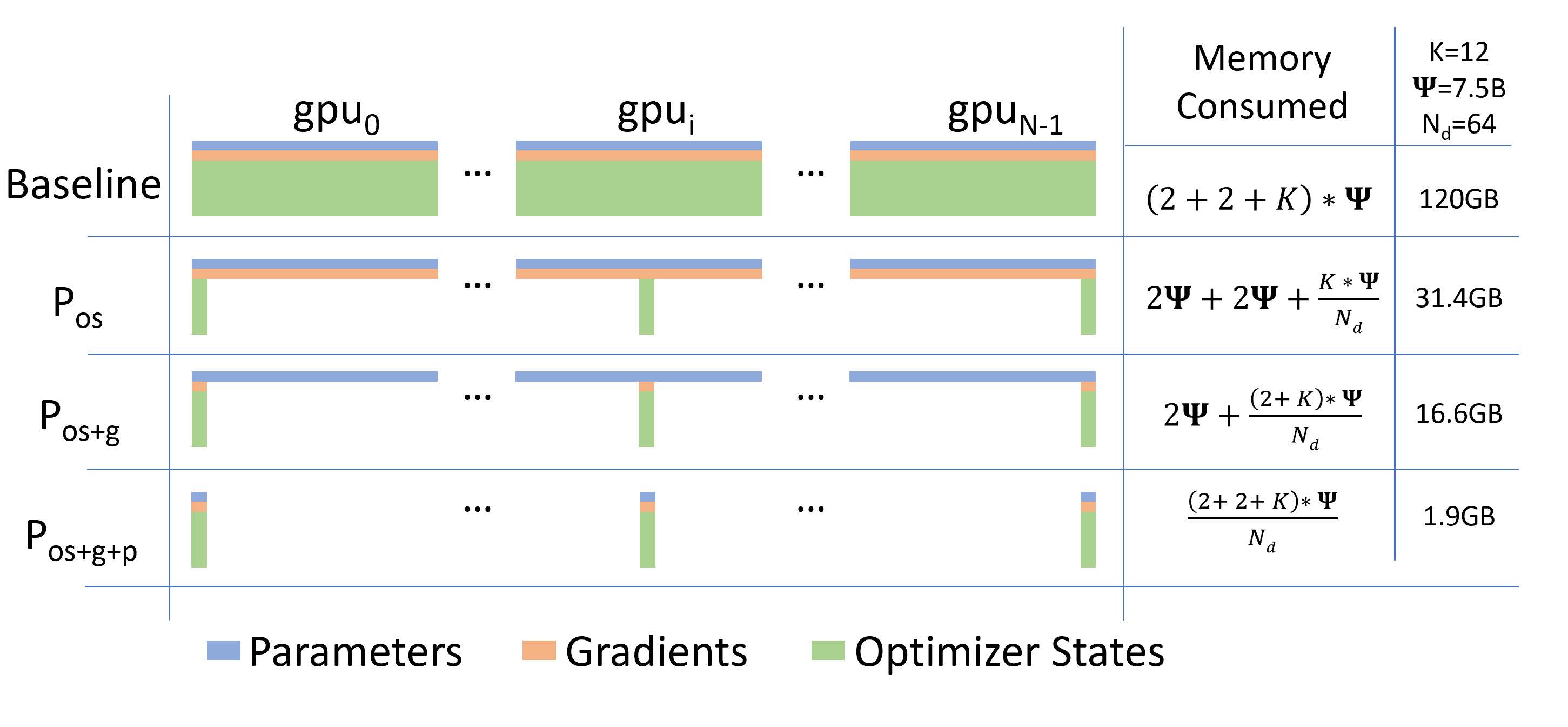
论文中给出了三个阶段的显存消耗分布情况:
# 2.1 ZeRO-1
模型训练中,正向传播和反向传播并不会用到优化器状态,只有在梯度更新的时候才会使用梯度和优化器状态计算新参数。因此每个进程单独使用一段优化器状态,对各自进程的参数更新完之后,再把各个进程的模型参数合并形成完整的模型。
假设我们有 个并行的进程,ZeRO-1 会将完整优化器的状态等分成 份并储存在各个进程中。当反向传播完成之后,每个进程的优化器会对自己储存的优化器状态(包括 Momentum、Variance 与 FP32 Master Parameters)进行计算与更新。更新过后的 Partitioned FP32 Master Parameters 会通过 All-gather 传回到各个进程中。完成一次完整的参数更新。
通过 ZeRO-1 对优化器状态的分段化储存,7.5B 参数量的模型内存占用将由原始数据并行下的 120GB 缩减到 31.4GB。
# 2.2 ZeRO-2
第二阶段中对梯度进行了拆分,在一个 Layer 的梯度都被计算出来后: 梯度通过 All-reduce 进行聚合, 聚合后的梯度只会被某一个进程用来更新参数,因此其它进程上的这段梯度不再被需要,可以立马释放掉。
通过 ZeRO-2 对梯度和优化器状态的分段化储存,7.5B 参数量的模型内存占用将由 ZeRO-1 中 31.4GB 进一步下降到 16.6GB。
# 2.2 ZeRO-3
第三阶段就是对模型参数进行分割。在 ZeRO3 中,模型的每一层都被切片,每个进程存储权重张量的一部分。在前向和后向传播过程中(每个进程仍然看到不同的微批次数据),不同的进程交换它们所拥有的部分(按需进行参数通信),并计算激活函数和梯度。
初始化的时候。ZeRO-3 将一个模型中每个子层中的参数分片放到不同进程中,训练过程中,每个进程进行正常的正向 / 反向传播,然后通过 All-gather 进行汇总,构建成完整的模型。