参考链接:https://blog.csdn.net/u012856866/article/details/140308083
# 一、引言
大多数语言模型都是通过生成 token 序列(sequence)中的下一个 token。每次模型生成下一个 token 时,会输入完整的 token 序列并预测下一个 token。这种策略被称为自回归生成(autoregressive generation)。
为了生成输出文本,在每一步预测下一个 token 的过程中,模型会给出一个概率分布,表示它对下一个单词的预测。例如,如果输入的文本是 “我最喜欢的”,那么模型可能会给出下面的概率分布:
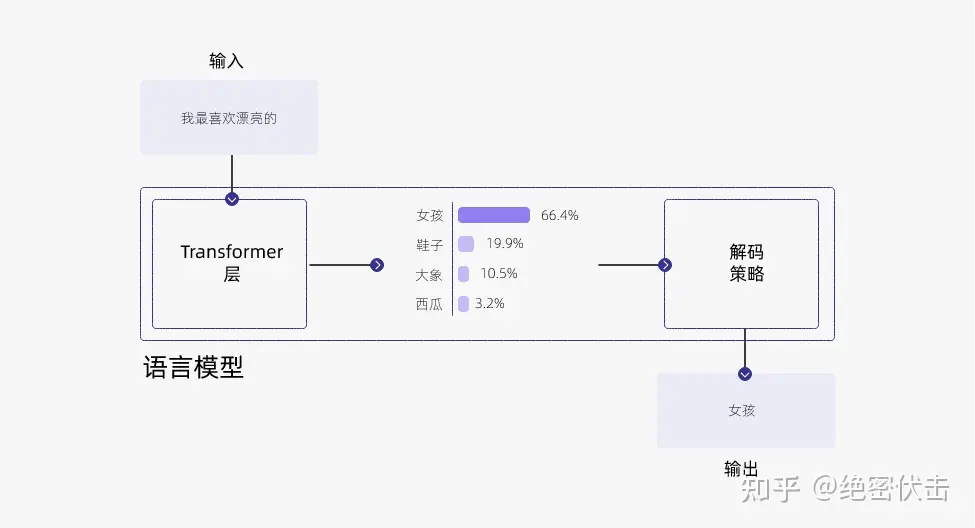
有如下几种常见的方法,来根据概率分布选择下一个单词:
- 贪心解码(Greedy Decoding):直接选择概率最高的单词。这种方法简单高效,但是可能会导致生成的文本过于单调和重复。
- 随机采样(Random Sampling):按照概率分布随机选择一个单词。这种方法可以增加生成的多样性,但是可能会导致生成的文本不连贯和无意义。
- Beam Search(集束搜索):维护一个大小为 k 的候选序列集合,每一步从每个候选序列的概率分布中选择概率最高的 k 个单词,然后保留总概率最高的 k 个候选序列。这种方法可以平衡生成的质量和多样性,但是可能会导致生成的文本过于保守和不自然。后续的 top-k、top-p 和 temperature 都是作用于单个束,如果存在多个束,则对每一个束单独执行 top-k、top-p 和 temperature 操作。
top-k 采样和 top-p 采样是介于贪心解码和随机采样之间的方法,也是目前大模型解码策略中常用的方法。
# 二、top-k 采样
Top-k 采样是对前面 “贪心策略” 的优化,它从排名前 k 的 token 中进行抽样,允许其他分数或概率较高的 token 也有机会被选中。在很多情况下,这种抽样带来的随机性有助于提高生成质量。
【top-k 采样思路】:在每一步,只从概率最高的 k 个单词中进行随机采样,而不考虑其他低概率的单词。
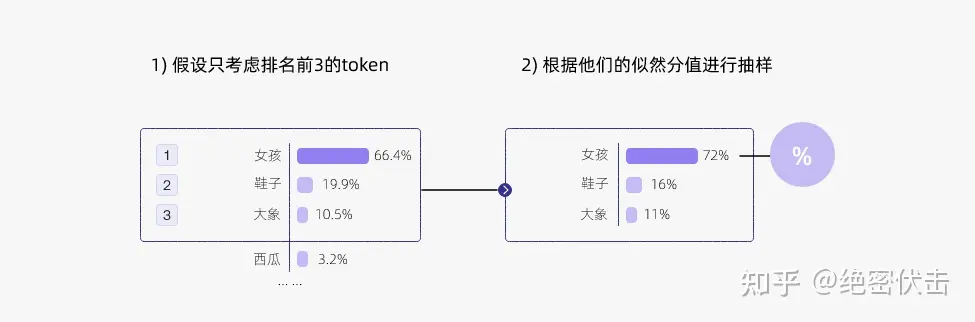
通过调整 k 的大小,即可控制采样列表的大小。“贪心策略” 其实就是 k = 1 的 top-k 采样。
# 三、top-p 采样
top-k 有一个缺陷,那就是 k 值的选取难以确定,于是出现了动态设置 token 候选列表大小策略 —— 即核采样(Nucleus Sampling)。
【top-p 采样思路】:在每一步,只从累积概率超过某个阈值 p 的最小单词集合中进行随机采样,而不考虑其他低概率的单词。这种方法也被称为核采样(nucleus sampling),因为它只关注概率分布的核心部分,而忽略了尾部部分。
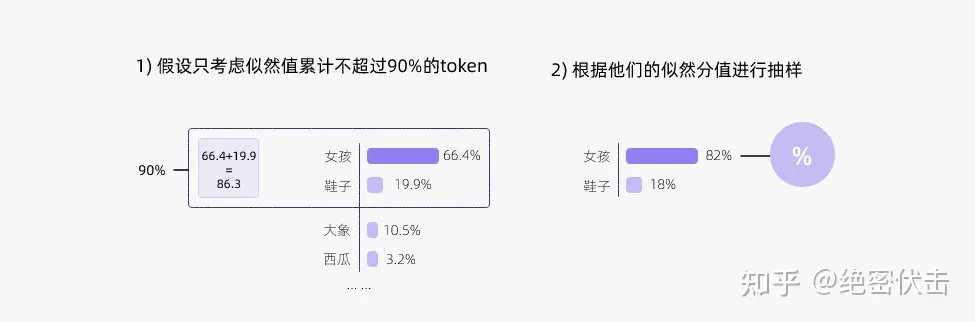
top-p 值通常设置为比较高的值(如 0.75),目的是限制低概率 token 的长尾。可以同时使用 top-k 和 top-p。如果 k 和 p 同时启用,则 p 在 k 之后起作用。
# 四、Temperature 采样
Temperature 采样受统计热力学的启发,高温意味着更可能遇到低能态。
Temperature 这个参数可以告诉机器如何在质量和多样性之间进行权衡。较低的 temperature 意味着更高的质量,而较高的 temperature 意味着更高的多样性
Temperature 采样公式时在 softmax 上加了一个超参数,用来平衡 diverse(多样性),一般的 softmax 公式如下:
加入温度超参数计算过程如下:
的值越大,概率分布就越接近于 uniform(均匀分布), 的值越小,概率密度就越几种在某几个 token 上,可以生成具有更小多样性的句子。

# 五、联合采样
通常将 top-k、top-p、Temperature 联合起来使用。使用的先后顺序是 top-k->top-p->Temperature。举例说明如下:
(1)首先设置 top-k = 3,表示保留概率最高的 3 个 token。这样就会保留女孩、鞋子、大象这 3 个 token。
女孩:0.664
鞋子:0.199
大象:0.105
(2)接下来,使用 top-p 的方法,保留概率的累计和达到 0.8 的单词,也就是选取女孩和鞋子这两个 token。
(3)最后使用 Temperature = 0.7 进行归一化,变成:
女孩:0.660
鞋子:0.340
接着,从上述分布中进行随机采样,选取一个单词作为最终的生成结果。
# 六、frequency penalty 和 presence penalty
频率惩罚和存在惩罚(frequency and presence penalties)。 这些参数是另一种让模型在质量和多样性之间进行权衡的方法。temperature 参数通过在 token 选择(token sampling)过程中添加随机性来实现输出内容的多样性,而频率惩罚和存在惩罚则通过对已在文本中出现的 token 施加惩罚以增加输出内容的多样性。
- 频率惩罚(frequency penalty):让 token 每次在文本中出现都受到惩罚。这可以阻止重复使用相同的 token / 单词 / 短语。
- 存在惩罚(presence penalty):一种固定的惩罚,如果一个 token 已经在文本中出现过,就会受到惩罚。这会导致模型引入更多新的 token / 单词 / 短语,从而使其讨论的主题更加多样化。
在不确定的情况下,将它们设置为零是一个最安全的选择!