参考链接:https://zhuanlan.zhihu.com/p/631398525https://zhuanlan.zhihu.com/p/676655352https://www.bilibili.com/video/BV1UT421k7rA/?spm_id_from=333.1007.top_right_bar_window_custom_collection.content.click&vd_source=e01172ea292c1c605b346101d7006c61、https://zhuanlan.zhihu.com/p/687832172
# 一、注意力机制简述
注意力机制从本质上讲和人类的选择性注意力机制类似,核心目标也是从众多信息中选出对当前任务目标更加关键的信息。最典型的注意力机制包括自注意力机制、空间注意力机制和时间注意力机制。这些注意力机制允许模型对输入序列的不同位置分配不同的权重,以便在处理每个序列元素时专注于最相关的部分。
最初的注意力机制将注意力汇聚的输出计算成为值的加权和。通过 Query 与 Key 的注意力汇聚(即,给定一个 Query,计算 Query 与 Key 的相关性,然后根据 Query 与 Key 的相关性去和对应的 Value 进行相乘)实现对 Value 的注意力权重分配,生成最终的输出结果。
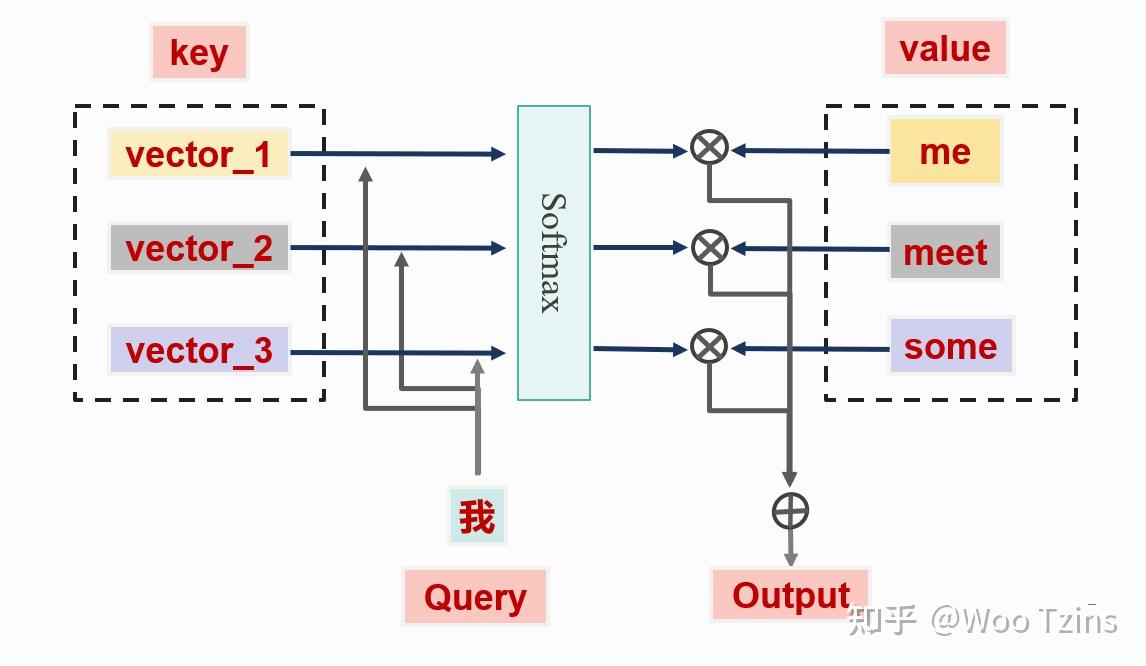
在上图中需要将中文的 "我" 翻译成英文的 "me",这就需要 "我" 和 "me" 之间的注意力分数相对于 "我" 和其他英文单词的要高。Query, Key,和 Value 的含义可以如下理解:
- Query:可以将 "我" 看作成 Query,因为 "我" 是当前要查询的目标,即当前输入的特征表示。
- Key:键矩阵里的数据用来计算这些词之间的相似度,可以将每个单词的重要特征表示看作成 Key。
- Value:值矩阵用来根据相似度计算出最终的输出结果,每个单词本身的特征向量看作为 Value,一般和 Key 成对出现,也就是我们常说的 "键 - 值" 对。
# 二、Transformer 的注意力层
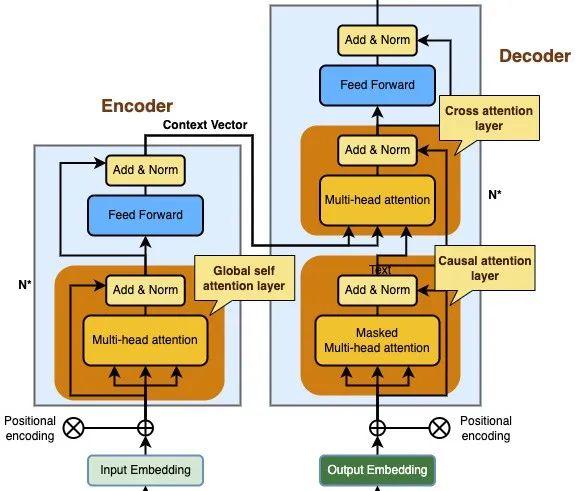
在 Transformer 架构中,有两大的组件,分别是编码器(Encoder)和解码器(Decoder), 编码器主要是将输入序列映射到潜在语义空间(注意力向量,也叫上下文向量),而解码器则是将注意力向量映射到输出序列。
在 Transformer 架构中,有 3 种不同的注意力层:
解码器中的交叉注意力层(Cross attention layer)
编码器中的全局自注意力层(Global self attention layer)
解码器中的因果自注意力层(Causal attention layer)
# 三、自注意力机制
在自注意力机制中,Query,Key,Value 均通过输入序列的 embedding 映射到。即
- Q = 输入序列中的当前位置词向量
- K = 输入序列中的所有位置词向量
- V = 输入序列中的所有位置词向量
key_layer = nn.Linear(in_features=d_model, out_features=d_model, bias=False, device=device) | |
query_layer = nn.Linear(in_features=d_model, out_features=d_model, bias=False, device=device) | |
value_layer = nn.Linear(in_features=d_model, out_features=d_model, bias=False, device=device) | |
q = query_layer(x) | |
k = key_layer(x) | |
v = value_layer(x) |
具体的操作为:
先根据 Query,Key 计算两者的相关性,然后再通过 softmax 函数得到 注意力分数,使用 softmax 函数是为了使得所有的注意力分数在 [0,1] 之间,并且和为 1。这里的重点在于如何计算 Query,Key 的相关性。Query,Key 的相关性公式一般表示如下:
其中 即表示自注意力机制,自注意力机制有很多变体,比如:加性注意力、缩放点积注意力等等。
之后根据注意力分数进行加权求和,得到带注意力分数的 Value,以方便进行下游任务。
# 3.1 加性注意力机制

加性注意力机制的核心思想是通过一个加性函数结合查询(Query)、键(Key)信息来计算注意力权重,之后再依据这些权重对值(Value)进行加权求和。其具体步骤如下:
- 输入映射:给定一个查询向量 和键向量 ,通过线性变换将 Query 和 Key 映射到一个共同的空间中,通常使用 和 。
- 加性融合与激活:对于每个键 ,将查询 与其进行加性融合,然后通过一个非线性激活函数(如 tanh 或 ReLU)来增强表达能力,最后将融合后的向量通过一个线性层(权重矩阵),上述两步的公式如下,其中 表示注意力函数
- 注意力权重计算:利用 softmax 函数,得到注意力权重,用于表示对每个值 的重视程度。具体公式如下:
- 加权求和:最后,根据计算出的注意力权重 对所有值向量 进行加权求和,得到最终的上下文向量:
# 3.2 缩放点积注意力机制

这是 Transformer 文章提出的注意力计算方法,缩放点积注意力机制的基本思想是,对于查询(Query)和一系列键值对(Key-Value Pairs)的集合,通过计算查询与每个键的点积,并利用 softmax 函数将这些点积转换为概率分布,以此来确定每个值的重要性,最终加权求和得到输出。具体如下:
- 点积计算:首先,对每个查询向量 与所有键向量 计算点积,生成原始匹配分数矩阵 ,即 S_{i}=q\cdot k_{i}^
- 缩放操作:然后,将上述匹配分数除以,以完成缩放操作,确保数值稳定性。上述两步的公式如下,其中 表示注意力函数
- 注意力权值计算:接下来,应用 softmax 函数到缩放后的分数上,将其转化为概率分布,反映了每个值相对于查询的重要性。
- 加权求和:最后,使用得到的概率分布对值矩阵 进行加权求和,生成最终的上下文向量 ,即每个查询位置的输出。以上步骤的公式如下:
# 三、交叉注意力机制
交叉注意力机制计算流程类似于自注意力机制,但有一个关键区别:自注意力机制中的查询、键和值都来自同一个输入序列,而交叉注意力机制的查询和键 / 值来自不同的输入序列。即:
- 查询 来自一个输入序列(如问题)。
- 键 和值 来自另一个输入序列(如段落或上下文)。
在 Transformer 中,交叉注意力层位于字面上的中心位置;它连接了编码器和解码器。
- Q = 解码器中因果注意力层的输出向量
- K = 编码器输出的注意力向量
- V = 编码器输出的注意力向量
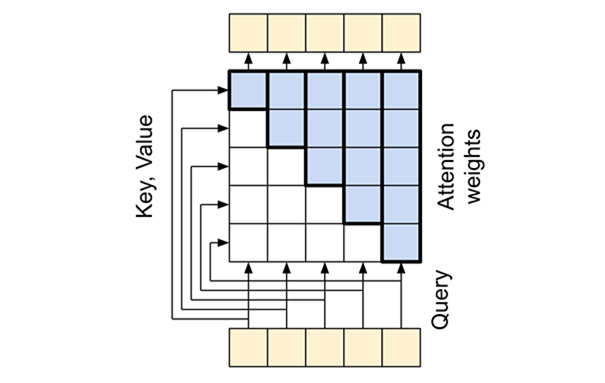
# 四、因果注意力层
因果注意力层对解码器中输出序列执行类似于全局自注意力层的工作;但与编码器的全局自注意力层有不同的处理方式。
Transformer 是一个 “自回归” 模型,每个序列元素的输出只依赖于前面的序列元素,模型具有 “因果” 性。
要构建一个因果自注意力层,在计算注意力分数和求和注意力值时需要使用适当的掩码,因为输出序列也是一次性输入的,但在计算前面分词的时候是不希望它后面的分词也参与计算的。
- Q = 输出序列中的当前位置词向量
- K = 输出序列中的所有位置词向量
- V = 输出序列中的所有位置词向量
# 五、其他注意力机制
# 5.1 Flash Attention
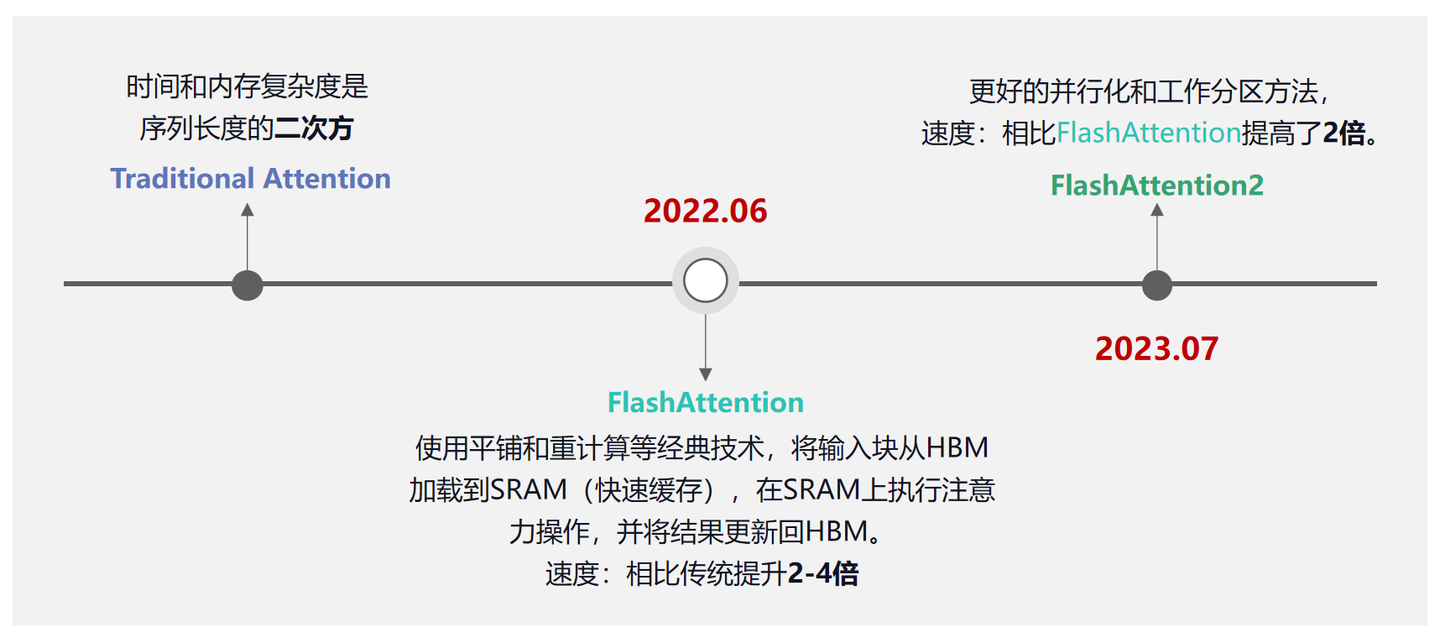
FlashAttention 旨在加速注意力计算并减少内存占用。FlashAttention 利用底层硬件的内存层次知识,例如 GPU 的内存层次结构,来提高计算速度和减少内存访问开销。 FlashAttention 的核心原理是通过将输入分块并在每个块上执行注意力操作,从而减少对高带宽内存(HBM)的读写操作。具体而言,FlashAttention 使用平铺和重计算等经典技术,将输入块从 HBM 加载到 SRAM(快速缓存),在 SRAM 上执行注意力操作,并将结果更新回 HBM。FlashAttention 减少了内存读写量,从而实现了 2-4 倍的时钟时间加速。
文章《FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness》在论文第一句指出 “Transformers are slow and memory-hungry on long sequences, since the time and memory complexity of self-attention are quadratic in sequence length.”,可以看出由于 Transformer 中 self-attention 的时间和内存复杂度是序列长度的二次方,所以序列过长时,算法速度会变慢,需要消耗很高的内存。
# (1) 预备知识
(1)HBM(High Bandwidth Memory, 高带宽内存)和 SRAM(Static Random-Access Memory, 快速缓存)
HBM 和 SRAM 是两种不同类型的计算机内存。
- HBM 是一种高带宽内存接口,用于 3D 堆叠的 SDRAM,具有较高的带宽和较低的功耗。
- SRAM 是一种静态随机访问存储器,用于高速缓存等内部存储器,具有更快的访问速度和更低的延迟,但成本更高且占用更多芯片空间。
下图是 GPU A100 的内存分布:

(2)MAC (Memory Access Cost,存储访问开销)
MAC(Memory Access Cost,存储访问开销)是指在计算机系统中,访问内存或存储器所需的时间和资源开销。它是衡量计算机程序或算法性能的重要指标之一。 MAC 的值取决于多个因素,包括内存层次结构、缓存命中率、内存带宽、存储器延迟等。较低的 MAC 值表示访问内存的开销较小,而较高的 MAC 值表示访问内存的开销较大。
# (2) FlashAttention 原理
传统 Attention 的计算过程如下:
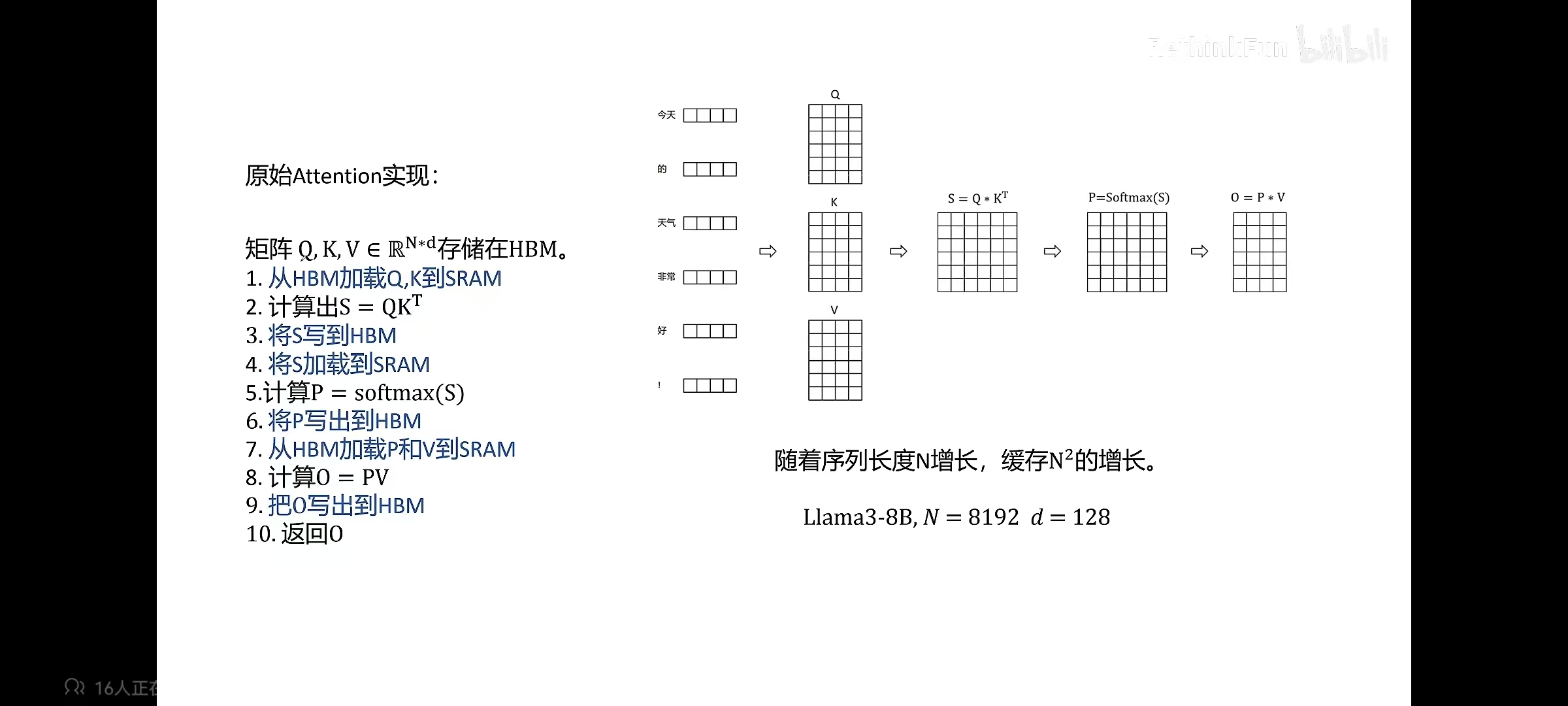
FlashAttention 的核心思想是减少 HBM 的读写,使用到的核心方法为分块计算,重新计算
- 分块计算:通过分块计算,融合多个操作,减少中间结果缓存
- 重新计算:反向传播时,重新计算中间结果
因为 Attention 计算中涉及 softmax,所以不能简单的分块后直接计算。softmax 操作是 row-wise 的,即每行都算一次 softmax,所以需要用到平铺算法来分块计算 softmax。FlashAttention 采用 safe softmax,来进行分块计算,具体的的过程如下:
